


The Dark Side Of The Semiconductor Design Renaissance – Fixed Costs Soaring Due To Photomask Sets, Verification, and Validation
The Dark Side Of The Semiconductor Design Renaissance – Fixed Costs Soaring Due To Photomask Sets, Verification, and Validation

We are in the midst of a semiconductor design renaissance. Nearly every major company in the world has their own silicon strategy as they try to become vertically integrated. There are also more chip startups than ever. The industry is rapidly shifting away from using Intel CPUs for everything. As Moore’s law slows, design is flocking towards heterogeneous architectures which are more specialized for their specific task. Specialized chips massively outperform CPUs if software challenges are solved, but there is a dark side to this specialization strategy. Fixed cost are exploding, and volumes are driven down massively for these designs. Semiconductors are an industry of economies of scale, and this is only becoming more apparent with each new technology generation.

Wafer manufacturing is a cycle of defining features with lithography and building them with deposition, etch, and other process steps. The leading edge of semiconductors involve using more than 60 unique layers of lithography and accompanying steps. Each of these layers necessitates a unique photomask. The collection of all the masks is called a mask set. These photomask sets convert the design from a chip architect to physical features. In the most laymen terms, a mask set can be thought of as a group of stencils which contains the design of a chip. Every unique chip design requires its own mask set.
There are many clever tricks that are being used to lower costs of designing that chip, but the biggest hinderances to bringing that design to market is the cost of a mask set. On a foundry process node, at 90nm to 45nm, mask sets cost on the order of hundreds of thousands of dollars. At 28nm it moves beyond $1M. With 7nm, the cost increases beyond $10M, and now, as we cross the 3nm barrier, mask sets will begin to push into the $40M range.
Special thanks to the SPIE Advanced Lithography + Patterning for providing many great presentations focused on masks, lithography, patterning, and metrology that identify this cost issue and how to scale from here.
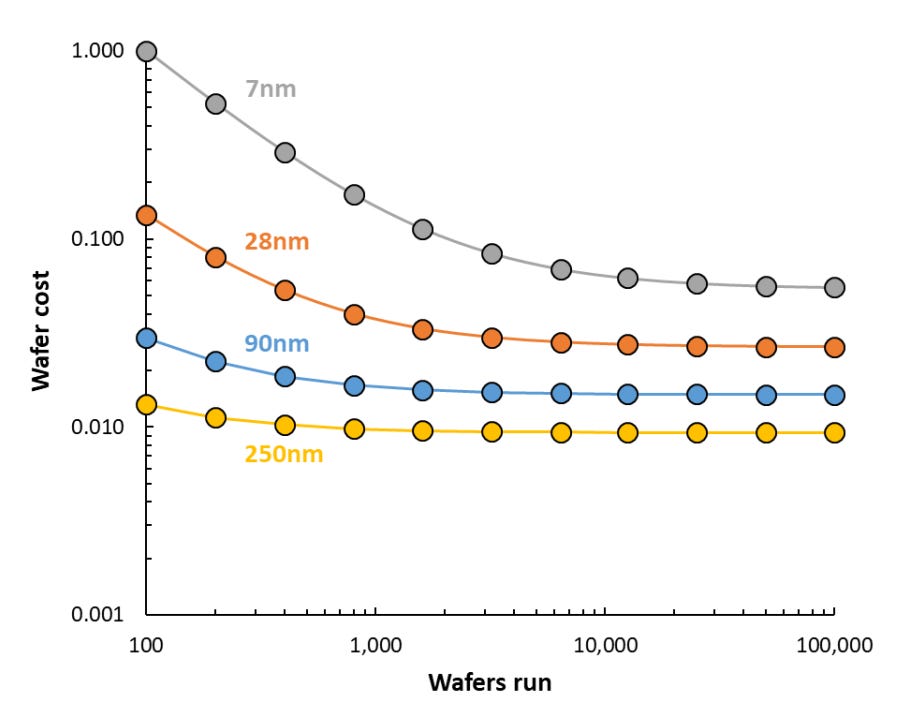
Wafer prices are increasing, but the cost of a mask set is increasing much more rapidly. The chart above from IC Knowledge demonstrates the conundrum. Volumes have to be significantly higher across eras of process technology to take advantage of the economic improvement from shrinking transistors.
Some folks are under the impression that transistor cost stopped falling at various process nodes such as 28nm, 7nm, 5nm, etc. The number of people claiming transistor cost have stopped falling and started increasing is seemingly doubling on a pace faster than Moore’s Law. To be clear, cost per transistor continues to fall even at 5nm and even 3nm foundry, but this is relegated to those who have large wafer volume. Chip design is expensive, but it is nowhere close to what IDC and McKinsey pretend it is. See the incorrect chart from them below.
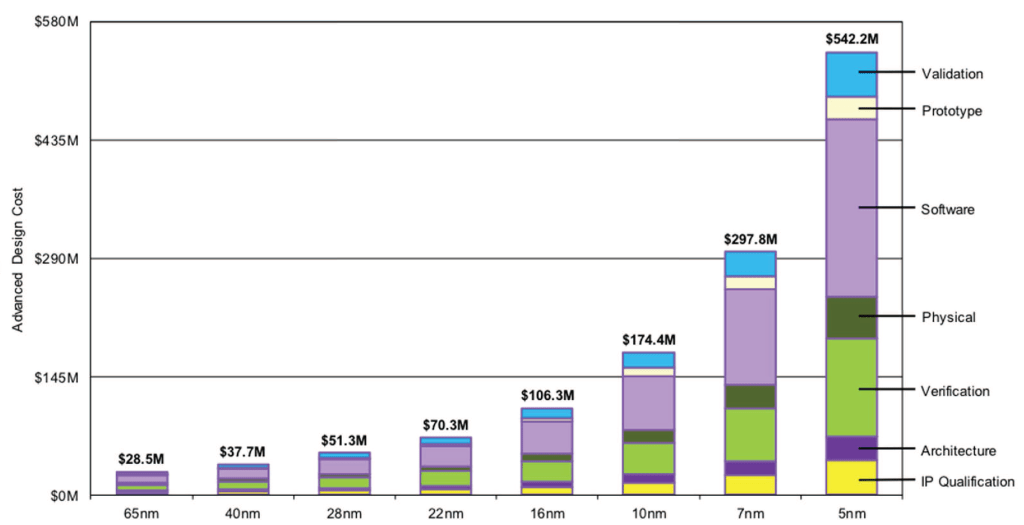
We have worked with multiple chip startups who have created leading edge chips on TSMC 7nm $50M to $75M. This cost includes their entire range of software, design, and tape out costs. These costs will vary wildly depending on the type of chip made.
As costs continue increasing as the industry advances in process technologies. More companies will not have volumes high enough to amortize their fixed costs associated to mask sets to take advantage of improving cost per transistor.
Startups and non-semiconductor companies who are just starting their journey into designing chips don’t only have to contend with hitting higher levels of volume to break even, they also must contend with the massive risks. The largest individual cost is design validation and verification. If the validation and verification pipelines are not up to snuff, the company risks massive product delays. These issues also apply to even the largest in the industry
Intel is behind in process technology, but with the latest stumbles from TSMC at 3nm, it is possible that Intel 4 and 3 process nodes will be competitive with TSMC’s best if Intel can ramp the nodes quickly. Even if Intel match TSMC on process technology, they have other hurdles which could prove to be insurmountable. The biggest problem Intel faces in our eyes is regarding their design validation and verification flows. To demonstrate, let’s look at Intel’s datacenter chips.
Ice Lake, Intel’s current server chip first powered on in December of 2018. The product launch was in April 2021, and the volume ramp wasn’t until Q3/Q4 of 2021. Intel likely first taped in their chip (aggregating IP to start making mask sets) for Icelake in early 2018. After tape-in, a tape out is when the first wafers run through a fab using the newly created mask set. Intel finished these wafers and packaged the chips to start testing in late 2018. This was the first spin of the chip, but Ice Lake required many new spins to become fully functional. Each new spin requires at least some new masks, generally on the critical layers, meaning a very high cost.
Intel’s next-generation server chip, Sapphire Rapids, faces similar issues in validation and verification. The first version of the Sapphire Rapids design powered on in June of 2020. Now, in mid-2022, Intel is still revising the design and mask sets due to issues they didn’t catch earlier in design. This is primarily due to validation and verification issues. Sapphire Rapids seems like it will launch in later 2022, but volume ramp is now expected in early 2023.
Intel’s validation and verification problems greatly increase costs and lengthen timelines. Having to revise masks isn’t a big issue on cost for Intel because their volumes are huge, but the delays are very impactful to their competitiveness. Each new revision requires at least some new masks, running wafers through the fab, and packaging the chip. This process takes a few months. For Ice Lake, it took Intel 6 revisions to ship, and Sapphire Rapids looks far more abysmal. They have done 12 steppings without it being fully validated for volume shipment. A0, A1, B0, C0, C1, C2, D0, E0, E2, E3, E4, and now E5.
In contrast, leading design firms who are considered the best in the business-like AMD and Nvidia take a fraction of the time. Nvidia who is known to have a very extensive custom simulation, validation, and verification flow, even takes less than a year in many cases. Intel can sort of afford these issues as they are such a juggernaut, even if it is what is causing their downfall. There are huge efforts to overhaul and fix this, and we are hopeful that Intel can, but this is a huge degree of skepticism.
Now imagine what happens to a startup or brand-new chip design team at a non-semiconductor firm if they stumble. These delays could kill a specific chip project like it has with Meta and Microsoft. These delays could even kill the entire companies or strategies. As the semiconductor design renaissance flourishes, it won’t all be rosy.
There will be a path of littered bodies from failed designs. More established firms likely will have some entirely vertical designs, but they will also pivot to semi-custom deals with Broadcom, Marvell, Intel, AMD, etc. The start-ups have it much rougher due to much more constrained budgets. We believe the flood of AI chip startups is likely to be the first place it shows up. There have already been layoffs at multiple high-profile AI startups, and that’s just the beginning. Despite this, there are many startups who will flourish and make a lot of money. This is a very high stakes game.
To keep costs of verification and respins low, the best ASICs are highly repetitious use of simple elements. Even if you take the time to customize the heck out of those elements, like Nvidia GPUs, overall the scale of the tools and the rules is local and then repeated to fill out the chip.
AMD is not that much faster than Intel. Sapphire Rapids had delays due to moving from Intel 7 to Intel 4. A good decision, but it is a reason for the maybe 7 respins. AMD have been talking up Genoa for years, so it was not super-quick. The interesting comparisons with Intel will be in the generation after SPR, when it looks like Intel will have the same kind of per-chiplet process specialization that AMD have pioneered, with similar advantages.
SPR is far more complex than an A100, in the sense that it has more specialized accelerators and other different kinds of functional units than Nvidia need to worry about. It is more interesting to compare Intel to Apple or to Qualcomm, other designers who have a ton of different functionality on their chips. These add to verification complexity.
The physical cost of making a mask is not so huge, if you separate it from design and verification cost. It takes a day or two of time on a dedicated ebeam machine to write the leading edge masks, plus some setup time to calculate how to modulate the ebeam machine to match the design. When a mask is respun for a correction, normally 99% of the mask does not change. This means that the respins should be a minor fraction of the costs associated with the mask set. Most of the cost is in the first mask set, that requires full validation, full rules check, and comprehensive corrections for predicted manufacturability. Those keep a large team of engineers and their most expensive tools busy for months. The iterations are a smaller loss of time plus payments for running the extra pilot set of wafers to check the design.
looks like even for 7nm, total fixed costs converge around 10k wafer run, that is, 10k is probably the floor for any independent ASICs. There's also an opinion that given current market situation, its versatility and programmability, Nvidia's A100 is still the cheapest option for data center AI service, which is bad news for start-ups. An interesting architecture is still long way from mass adoption. By the way, why is Intel's cost for verification and validation per node much higher and takes longer than AMD and Nvidia? Is it because Intel did it in-house and competitors outsourced?