


Rebuilding Intel – Foundry vs IDM Decades of Inefficiencies Unraveled
Rebuilding Intel – Foundry vs IDM Decades of Inefficiencies Unraveled
Foundry Cost, Hot Lots, Steppings, Tool Utilization, Test & More: Path to Operational Efficiency?


Intel holds a unique position in the semiconductor industry as the only major Integrated Design Manufacturer (IDM), meaning they both design and manufacture their own advanced chips as a single firm. While Samsung has both functions, there is effectively a firewall between LSI (design) and foundry. Intel’s unique position as an IDM is both a major structural advantage and disadvantage. Today we want to talk through the inefficiencies of Intel on a technology and cost basis. In addition to Intel’s claims, we will share our independent opinion on the technology, cost modeling, and gross margin for Intel.
Theoretically, Intel can optimize their manufacturing and designs for each other more closely than a competitor like AMD can with TSMC due to being a single firm with fewer data-sharing restrictions. They can price their final chips lower than AMD can because there is no external TSMC foundry tax to pay.
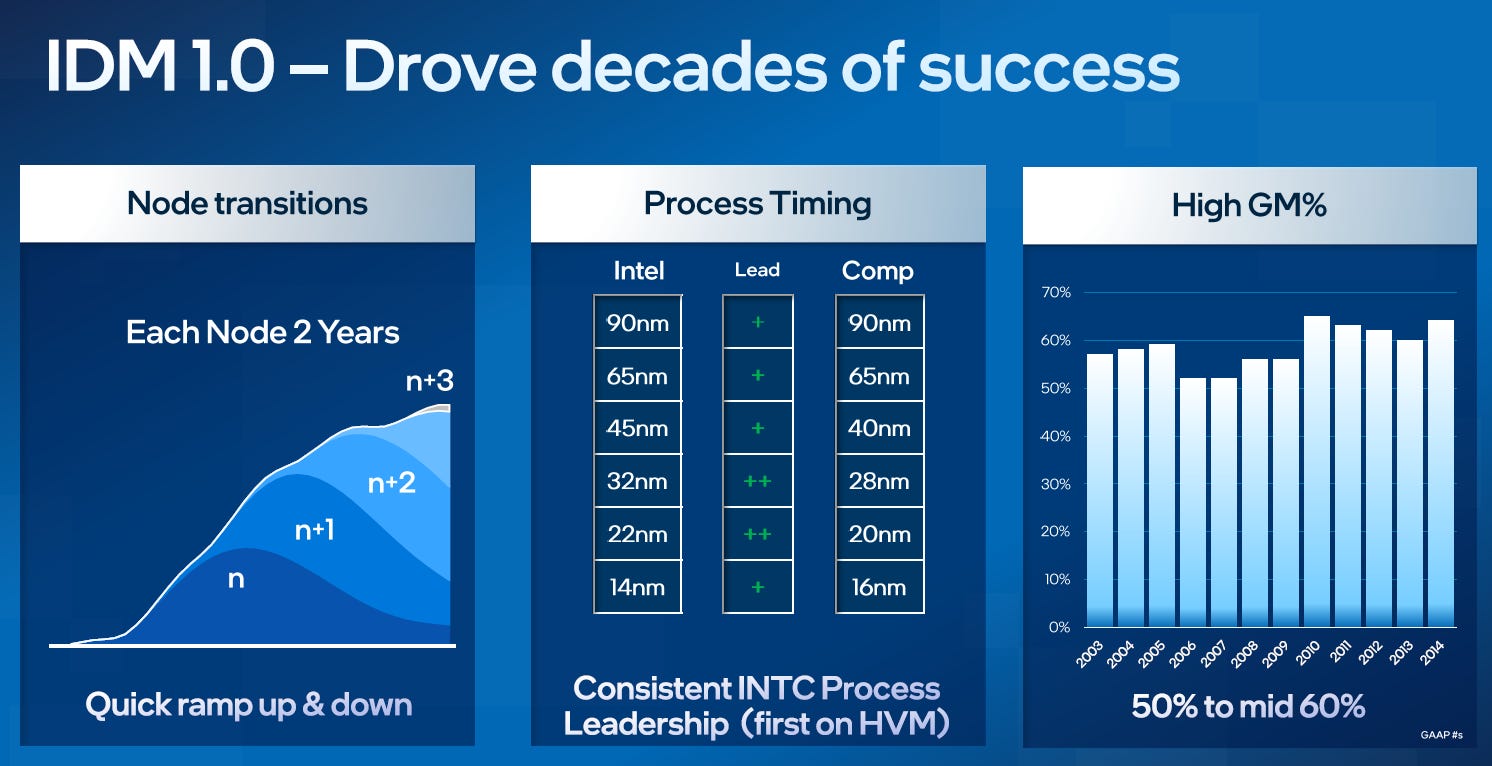
For decades this model worked and held true. Intel had a huge process node lead over all of its competitors and therefore was able to dominate. They consistently had higher margins than firms like TSMC and AMD. The image below shows what a combined foundry + fabless company would look like if they were hypothetically the same company versus Intel.

The process node advantage began showing cracks in the early 2010s with 14nm, but then it fell completely apart at the 10nm transition, originally scheduled for 2016. The foundries raced ahead through 16nm, 10nm, and 7nm lapping up Intel’s 3-year lead and turning it into a 3-year deficit.
Some of these cracks were due to being a massive IDM. Responsibility and accountability were not properly pushed down to individual teams and business units. Sections of Intel withered away and were behind the industry in performance or cost, but no one could tell because Intel was in its own la-la-land of overwhelming engineering dominance.

Once Intel lost that lead, the inefficiencies became clear. Today, Intel is significantly less efficient at manufacturing wafers than TSMC. Intel requires more fab space for the same output due to lower tool utilization rates and worse yields.
Meanwhile Intel’s design teams are meaningfully behind AMD’s, requiring larger cores with more transistors that guzzle more power to achieve similar performance. Furthermore, Intel’s design teams take many more years and higher cost to reach production for a new architecture due to their inferior design methodology.
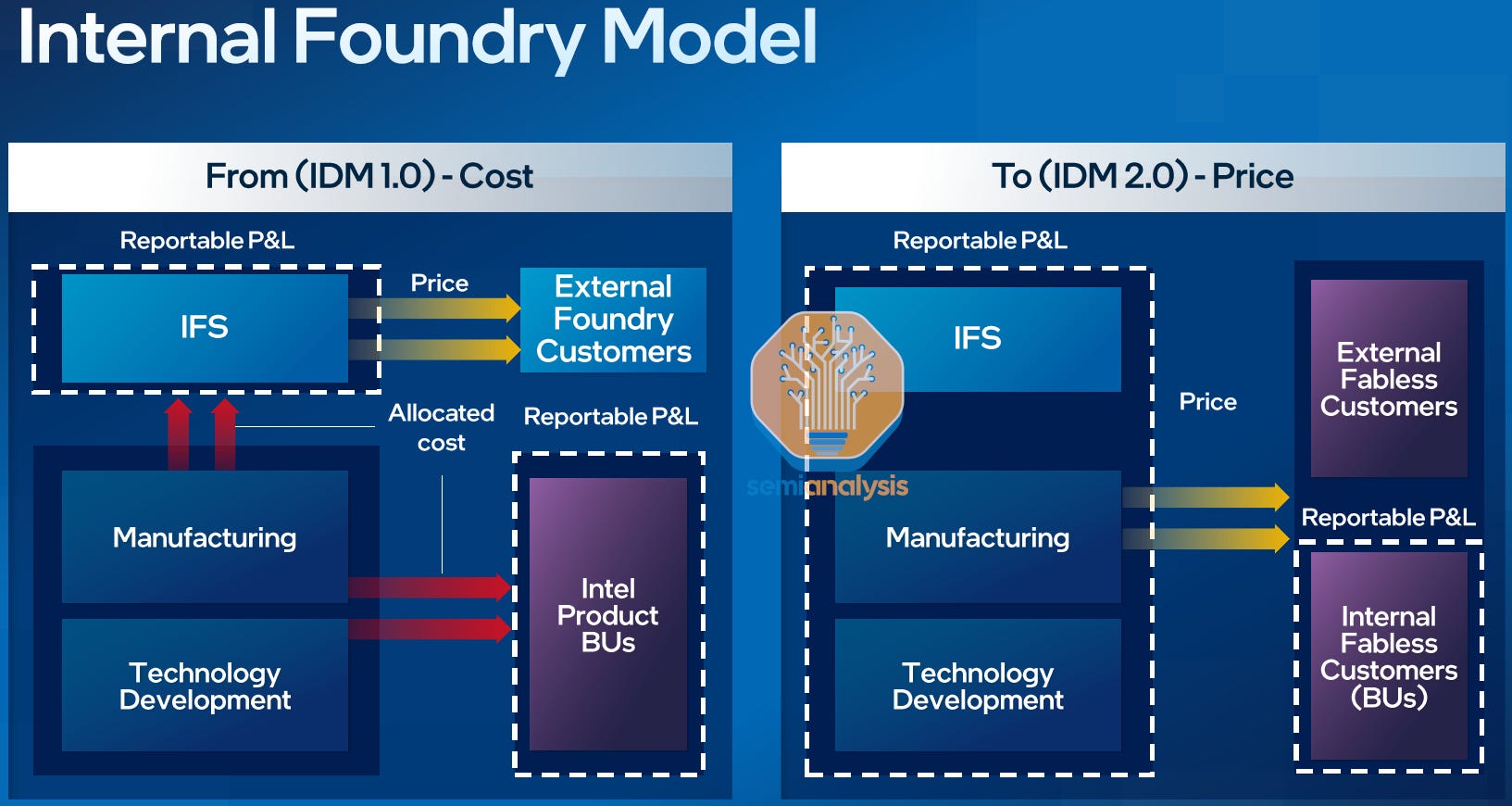
One of Intel’s solutions for these issues is to catch up on process nodes, by shrinking twice in rapid succession (Intel 4/3 and Intel 20A/18A). That alone won’t solve the issues, though, as they still lack the scale, customer base, and operating efficiencies.
Intel is currently in the midst of trying to fix many of these issues and transitioning into becoming an external foundry for a variety of customers externally. While on the surface, this only helps if they can win external customers, there are other advantages.
By moving to an internal foundry model, Intel can begin to end the nonsense practice of allocating costs to entire business units instead of individual designs and teams. This will help solve some of their major inefficiencies by driving accountability down to a lower level which will help manage costs on a product and fab level.
Current Inefficiencies
These various issues are overwhelming and have lead to the current Intel we see today. In general, Intel product teams could hide behind their manufacturing prowess and shrug off costs that were allocated to the entire business unit.
Hot Lots
In semiconductor manufacturing, wafers are manufactured in batches known as lots. These lots are a collection of wafers that get processed sequentially by a tool before moving on to the next available tool for manufacturing. Because a fab costs tens of billions of dollars, the fab’s tools must be maximally utilized. Generally, a leading edge wafer can take 10 weeks to be processed due to this batching of wafers into lots.
On the other hand, a leading-edge wafer can also be processed in a few weeks if no care is given to cost, but this leads to tremendous inefficiency with tools constantly waiting for the wafer so it can be processed as quickly as possible. This is called a "hot lot" which refers to a batch of wafers that are given priority and processed more quickly than standard lots.
They could do as many hot lots as they want, they can do as many samples as they want.
David Zinsner, Intel CFO
This can be for a variety of reasons, such as to expedite the validation of a new process step or tool, or to create test chips for a new design or technology. The term comes from the idea that these wafers are "hot" because they're being pushed through the fabrication process as fast as possible.
We do use a lot of hot lots. And typically, as a GM, I don't always think as hard about that as I probably should in terms of the cost of hot lots -- not just the cost but the disruption to the factory in terms of their utilization and efficiency.
Sandra Rivera, EVP and GM of Intel Datacenter and AI Group
However, running hot lots can indeed decrease tool utilization and overall fab efficiency. Therefore, it's a trade-off between the urgency of getting specific wafers processed quickly versus the overall efficiency and throughput of the fabrication plant.
Our benchmarking suggests that we expedite materials around 2 to 3x more than our industry peers with an estimated 8% to 10% hit in overall output.
Jason Grebe, VP and GM of Intel Corporate Planning Group
Intel is fixing this issue by moving to the internal foundry model and charging business units for hot lots just like any other foundry charges their customers for these hot lots.
Intel believes this change alone could save them $500M to $1B annually.
Steppings & Samples
Designing a chip is incredibly costly. Once you have a complete design, bringing it to production involves sending the design to the fab, converting those designs into dozens of physical photomasks to place inside the lithography tools, and running test chips through thousands of process steps. Once test chips are received, they can be reviewed for bugs/issues, and the design can be tweaked.
We have discussed the design costs problem in detail for the industry here, but one of the areas that is currently a major disadvantage for Intel is that they take more of these iterations. A stepping is when a modified design is sent to the fab, and new photomasks are created for new test chips.
They can do as many steppings as they want.
David Zinsner, Intel CFO
It took Intel 12 steppings to bring Sapphire Rapids to market, whereas AMD usually takes only 2 to 3 steppings for competing chips such as Bergamo and Genoa. This creates a tremendous increase in costs for Intel to create all these additional photomasks as well as massively increasing the time to bring new designs to market.

We even heard rumors from former employees that there was a time when some Intel design teams would rather send a design to the fabs, get a hot lot sample back, and test it for bugs rather than complete more through simulations and verification.
Intel plans to fix this issue by reducing the number of samples and steppings by charging the design and product business units a fair price for these operations rather than allowing as many steppings as wanted. The design teams began shifting to more industry-standard design methodologies a few years ago, although that task is monumental.
Intel believes this change would save them $500M to $1B annually.
Test, Sort, Bin
After chips are fabbed, they are tested and sorted for failures and various bins to go into different products. Intel was a pioneer for many years in test, sort, and binning. Their tools are highly customized, and they have many unique in-house test patterns. While this gives Intel some advantages over the industry, it’s not all positive.
We've increasingly grown our test times compared to our industry peers. Currently, we estimate our test times are 2 to 3x those of our competitors. Effectively, our lower-cost testing platform was subsidizing the growth in our test times.
Jason Grebe, VP and GM of Intel Corporate Planning Group
This tremendous manufacturing capability advantage Intel had in the past, again turned into a disadvantage. The test times have no business being 2x to 3x that of a competitor like AMD, given final chip field reliability is not really differentiated.
Intel believes charging business units more directly for test, sort, and bin will make the business units more conscious about what test strategies they use within designs and lead to savings of ~$500M a year.
Furthermore, Intel’s advanced binning strategies lead to them having a product strategy we like to call “SKU Spam.” In PC and Datacenter, Intel has dozens and dozens of SKUs because they are able to sort the chips into so many bins for final end market chips. Compare this to AMD, Broadcom, and Nvidia whose product stacks are far more simplified, there is a clear potential for cost savings by reducing the number of SKUs, but we haven’t heard of any Intel plans shift away from this yet.
Design and Ramp
Product managers and design teams used to hide their architectural inefficiencies with Intel’s manufacturing prowess. With the internal foundry model, this changes as products with bloated die sizes, such as Sapphire Rapids, would immediately hit the cost structure for that team rather than be swallowed up by the manufacturing organization. As such, these changes will make teams place a new emphasis on architecture, die size, and resulting cost.
Intel believes that would save more than $1B a year as teams can more easily identify what features are worth spending the die area on versus not. Currently, Intel’s Sapphire Rapids spends a lot of area on features that most customers do not use.
Intel design teams also tend to ignore the reticle conundrum and lithography tool throughput issues for internal manufacturing, which is something TSMC charges customers for. For a deeper explanation, see here.

Intel did not say whether they would start charging internal foundry customers for this.
Intel is also squarely focusing on the ramp rate as a method of cost scaling. TSMC’s greatest strength is that their 7nm and 5nm high volume ramps went from 0 wafers per month to 50,000 wafers per month within a 6-month period. This gives them an earlier period for yield learnings to be recognized and passed on for the rest of the node’s lifespan. It also increases tool utilization. It should be noted that TSMC’s 3nm ramp is much more paltry due to various stumbles and cost issues, resulting in Apple moving to a split SOC methodology.
If Intel wants to catch up, they need to be able to ramp up much faster. Ice Lake and Sapphire Rapids ramps were incredibly slow, resulting in poor capital utilization and slower yield learnings. Intel is now going to charge internal teams a flat wafer price across the lifetime of a node to try to accelerate the ramp speed for new products, which could both save $1B annually, according to Intel as well as increase the speed of getting new competitive products out to market.
Much like TSMC, Intel will also begin to charge teams for their utilization and lock in orders earlier. They will begin to also be less flexible to their internal customers on orders of wafers.
They can change their forecast pretty much every week if they wanted to do that.
David Zinsner, Intel CFO
This change will help increase tool utilization due to being able to plan better production, which will also be a massive saving.

Overall, Intel has a lot of claims on cost savings from various changes to the internal foundry model.
Now let’s dive into our analysis on Intel’s cost as well as our outlook on their technology competitiveness. 2024 is shaping up to be a rough year, but have they turned the corner?