


The Inference Cost Of Search Disruption – Large Language Model Cost Analysis
The Inference Cost Of Search Disruption – Large Language Model Cost Analysis
$30B Of Google Profit Evaporating Overnight, Performance Improvement With H100 TPUv4 TPUv5


OpenAI’s ChatGPT took the world by storm, quickly amassing over 100 million active users in January alone. This is the fastest any application has ever grown to this size, with the prior two record keepers being TikTok at 9 months and Instagram at 2.5 years. The top question on everyone’s mind is how disruptive large language models (LLMs) will be for search. Microsoft rocked the world this week with their Bing announcement, incorporating OpenAI’s technology into search.
This new Bing will make Google come out and dance, and I want people to know that we made them dance.
Google’s recent actions make it look like they are dancing. While we believe Google has better models and AI expertise than any other firm in the world, they do not have a culture conducive to implementing and commercializing much of its leading technology. The competitive pressures from Microsoft and OpenAI are changing this rapidly.
Disruption and innovation in search don’t come for free. The costs to train an LLM, as we detailed here, are high. More importantly, inference costs far exceed training costs when deploying a model at any reasonable scale. In fact, the costs to inference ChatGPT exceed the training costs on a weekly basis. If ChatGPT-like LLMs are deployed into search, that represents a direct transfer of $30 billion of Google’s profit into the hands of the picks and shovels of the computing industry.
Today we will dive into the differing uses of LLMs for search, the daily costs of ChatGPT, the cost of inference for LLMs, Google’s search disruption effects with numbers, hardware requirements for LLM inference workloads, including performance improvement figures for Nvidia’s H100 and TPU cost comparisons, sequence length, latency criteria, the various levers that can be adjusted, the differing approaches to this problem by Microsoft, Google, and Neeva, and how the model architecture of OpenAI’s next model architecture, which we detailed here dramatically reduces costa on multiple fronts.
The Search Business
First off, let’s define the parameters of the search market. Our sources indicate that Google runs ~320,000 search queries per second. Compare this to Google’s Search business segment, which saw revenue of $162.45 billion in 2022, and you get to an average revenue per query of 1.61 cents. From here, Google has to pay for a tremendous amount of overhead from compute and networking for searches, advertising, web crawling, model development, employees, etc. A noteworthy line item in Google’s cost structure is that they paid in the neighborhood of ~$20B to be the default search engine on Apple’s products.
Google’s Services business unit has an operating margin of 34.15%. If we allocate the COGS/operating expense per query, you arrive at the cost of 1.06 cents per search query, generating 1.61 cents of revenue. This means that a search query with an LLM has to be significantly less than <0.5 cents per query, or the search business would become tremendously unprofitable for Google.
We’re excited to announce the new Bing is running on a new, next-generation OpenAI large language model that is more powerful than ChatGPT and customized specifically for search. It takes key learnings and advancements from ChatGPT and GPT-3.5 – and it is even faster, more accurate and more capable.
ChatGPT Costs
Estimating ChatGPT costs is a tricky proposition due to several unknown variables. We built a cost model indicating that ChatGPT costs $694,444 per day to operate in compute hardware costs. OpenAI requires ~3,617 HGX A100 servers (28,936 GPUs) to serve Chat GPT. We estimate the cost per query to be 0.36 cents.
Our model is built from the ground up on a per-inference basis, but it lines up with Sam Altman’s tweet and an interview he did recently. We assume that OpenAI used a GPT-3 dense model architecture with a size of 175 billion parameters, hidden dimension of 16k, sequence length of 4k, average tokens per response of 2k, 15 responses per user, 13 million daily active users, FLOPS utilization rates 2x higher than FasterTransformer at <2000ms latency, int8 quantization, 50% hardware utilization rates due to purely idle time, and $1 cost per GPU hour.
Please challenge our assumptions; we would love to make this more accurate, although we believe we are in the correct ballpark.
Search Costs With ChatGPT
If the ChatGPT model were ham-fisted into Google’s existing search businesses, the impact would be devastating. There would be a $36 Billion reduction in operating income. This is $36 Billion of LLM inference costs. Note this is not what search would look like with LLMs, that analysis is here.
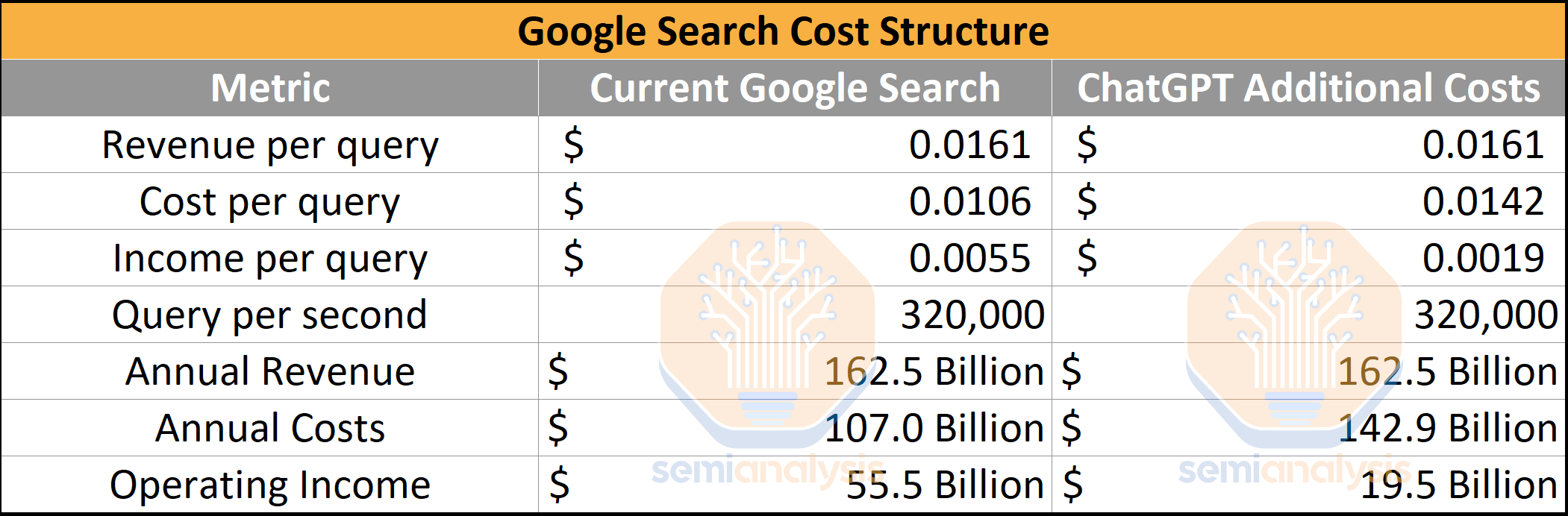
Deploying current ChatGPT into every search done by Google would require 512,820.51 A100 HGX servers with a total of 4,102,568 A100 GPUs. The total cost of these servers and networking exceeds $100 billion of Capex alone, of which Nvidia would receive a large portion. This is never going to happen, of course, but fun thought experiment if we assume no software or hardware improvements are made. We also have inference costs using Google’s TPUv4 and v5 modeled in the subscriber section, which are pretty different. We also have some H100 LLM inference performance improvement figures as well.
The amazing thing is that Microsoft knows that LLM insertion into search will crush the profitability of search and require massive Capex. While we estimated the operating margin shift, check out what Satya Nadella says about the gross margin.
From now on, the [gross margin] of search is going to drop forever.
This doesn’t even account for the fact that search volumes likely decrease somewhat as search quality improves, the difficulties in inserting ads into an LLM’s response, or a myriad of other technical issues that we will discuss later in this report.
Microsoft is happily blowing up the profitability of the search market.
For every one point of share gain in the search advertising market, it’s a $2 billion revenue opportunity for our advertising business.
Bing has a meager market share. Any share gains Microsoft grabs will give them tremendous top-line and bottom-line financials.
I think there’s so much upside for both of us here. We’re going to discover what these new models can do, but if I were sitting on a lethargic search monopoly and had to think about a world where there was going to be a real challenge to the way that monetization of this works and new ad units, and maybe even a temporary downward pressure, I would not feel great about that.
There’s so much value here, it’s inconceivable to me that we can’t figure out how to ring the cash register on it.
Meanwhile, Google is on the defensive. If their search franchise falters, they have a tremendous problem with their bottom line. Share losses will look even worse than the analysis above as Google is quite bloated in operating costs.
Google’s Response
Google isn’t taking this lying down. Within just a couple of months of ChatGPT’s release, Google is already putting their version of search with an LLM into the public sphere. There are advantages and disadvantages from what we have seen on the new Bing vs. the new Google.
Bing GPT seems tremendously more potent in terms of LLM capabilities. Google has already had issues with accuracy, even in their on-stage demonstrations of this new technology. If you measure both Bing GPT and Google Bard response time, Bard crushes Bing in response time. These model response time and quality differences are directly related to model size.
Bard combines the breadth of the world’s knowledge with the power, intelligence, and creativity of a large language model. It draws on the information from the web to provide fresh and high-quality responses. We’re releasing it initially with our lightweight model version of LaMDA. This much smaller model requires significantly less computing power, enabling us to scale to more users, allowing for more feedback.
Google is playing defense on margins with this smaller model. They could have deployed their full-size LaMDA model or the far more capable and larger PaLM model, but instead, they went for something much skinnier.
This is out of necessity.
Google cannot deploy these massive models into search. It would erode their gross margins too much. We will talk more about this lighter-weight version of LaMDA later in this report, but it’s important to recognize that the latency advantage of Bard is a factor in its competitiveness.
Since Google’s search revenue is derived from ads, different users generate different revenue levels per search. The average suburban American woman is much more revenue per targeted ad than a male farmer in India. This also means they generate vastly different operating margins too.

The Future of Large Language Models In Search
Ham fisting an LLM directly into search is not the only way to improve search. Google has been using language models within search to generate embeddings for years. This should improve results for the most common searches without blowing up inference cost budgets because those can be generated once and served to many. We peel that onion here and some of the numerous cost optimizations that can be done.
One of the biggest challenges with inserting LLM into search is sequence length growth and low latency criteria. We will discuss those below and how those will shape the future of search.
We will also discuss Nvidia A100, H100, and Google’s TPU in the context of LLM inference and costs per query. We will also be sharing H100 inference performance improvement and the impact that it will have on the hardware market. The competitiveness of GPU vs. TPU is inherent in this battle.
Furthermore, the cost per inference can be significantly reduced without new hardware. We discussed OpenAI’s next LLM architecture improvement on the training side here, but there are also improvements in inference costs. Furthermore, Google is also utilizing some unique, exciting techniques that we will also discuss below.