


Tenstorrent Wormhole Analysis - A Scale Out Architecture for Machine Learning That Could Put Nvidia On Their Back Foot
Tenstorrent Wormhole Analysis - A Scale Out Architecture for Machine Learning That Could Put Nvidia On Their Back Foot

Tenstorrent has had significant media coverage for being one of the foremost AI startups. In addition to promising hardware and software design, a portion of the hype is because they have the semiconductor titan, Jim Keller. He has been an investor since the beginning stages of the firm when he was working at Tesla. After his stint at Tesla, he worked at Intel before finally coming on board as the CTO in the beginning of 2021.
Tenstorrent takes a unique approach of tightly intertwined hardware and software. The hardware is specialized for the task, but the software is not egregiously complicated. The entire software stack is only about 50,000 lines of code. Unlike most other AI specific ASICs which require a custom development pipeline, Tenstorrent is very adaptable and flexible while supporting all major toolchains, frameworks, and runtime. Nvidia’s largest advantage of being extremely easy to develop on is being challenged.
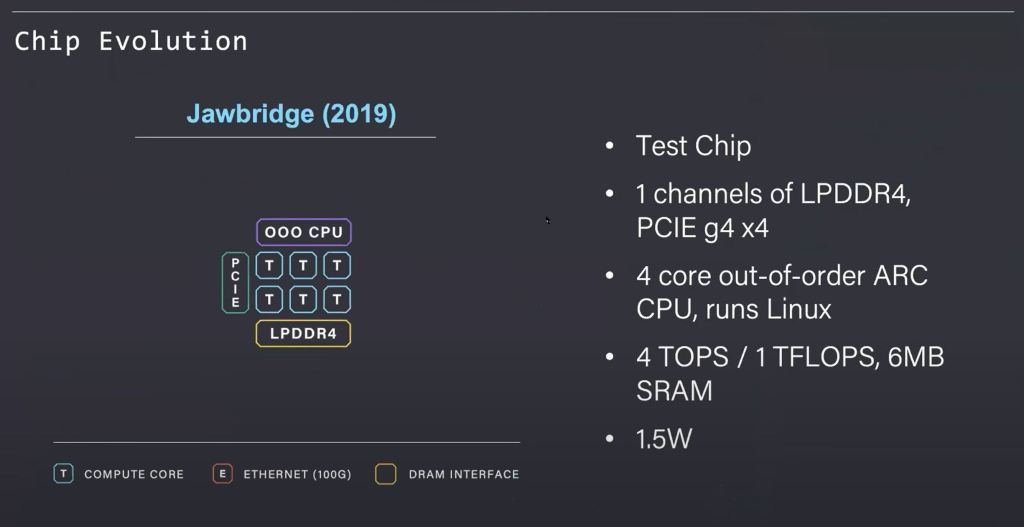
To understand their architecture and the Wormhole processor, we will walk through the history and linage that comes before it. Jawbridge was a small testchip that was developed as a proof of concept for the architecture. There is an array of Tenstorrent designed “Tensix” processing cores, connected by the in-house network on chip (NOC). This is coupled with licensed I/O blocks such as LPDDR memory controllers and PCIe roots. The on-die CPU cores can manage the workload and run Linux.
Jawbridge is an extremely small chip with exceptionally low power requirements. With the shoestring budget, they taped this chip out and validated their impressive power/performance claims. Based on the back of this proof of concept, they were able to raise more funding to scale forward to the next generation.

GraySkull is the next evolution, and it is a commercial product. This chip has 128 Tensix cores, the all-important NOC scales up heavily, IO is much larger. This chip is 620mm^2 on the GlobalFoundries 12nm process. A testament to Tenstorrent design prowess is that they are shipping A0 silicon. This means they designed the chip correctly and found no erratum on their first tapeout. This is a fete that is very uncommon within the industry even for very seasoned teams at companies such as AMD, Apple, Intel, and Nvidia.
GraySkull is a 65W chip, but the PCIe add in card is 75W. This means it can slot into existing servers easily without any additional auxiliary power required. After completing tape out and sampling, Tenstorrent was able to raise even more money to fund their next generation chip.


This brings us to Wormhole, it is a 670mm^2 die on the same GlobalFoundries 12nm process node. Despite the small increase in silicon area and utilization of the same node, Tenstorrent was able to significantly scale performance, IO, and scalability. The biggest departure from previous designs besides being more performant and power hungry is that they added 16 ports with 100Gb ethernet. The ethernet ports allow many chips to be linked together to scale out for large AI networks.

In addition to scaling up with ethernet, each Tensix core receives a large upgrade. They now house more SRAM per core and can execute more complex math and SIMD instructions. Wormhole includes a 192 bit GDDR6 memory bus capable of 384GB/s of memory bandwidth. Despite 2x the performance in matrix operations, nearly 3x the memory bandwidth, and inclusion of 1.6Tbs of networking switching capabilities, the Wormhole chip only doubles in power to 150W.
Tenstorrent has done the equivalent of black magic to achieve these goals on the same 12nm process technology and less than 10% increase in die area. The network on chip (NOC) is smartly designed to natively be extended over the ethernet ports. Chip to chip communications require 0 software overhead for scale out AI training.

AI training workloads are soaring in complexity. OpenAI claims that the amount of compute required to train the most powerful networks doubles every 3.5 months. Facebook recently announced their new production deep learning recommendation system is 12 trillion parameters. This exceeds the OpenAI trend. Training these networks requires not just servers, but entire racks of AI dedicated servers. The ability to scale out to massive networks with ease is a key strength of Tenstorrent’s Wormhole.
The Wormhole chip will be offered in two variants. One is an add in PCIe card which can easily slot in to servers. Customers with truly massive AI training problems will want to purchase the module instead. This brings the full capabilities of this chip to bear with all ethernet networking capabilities exposed.
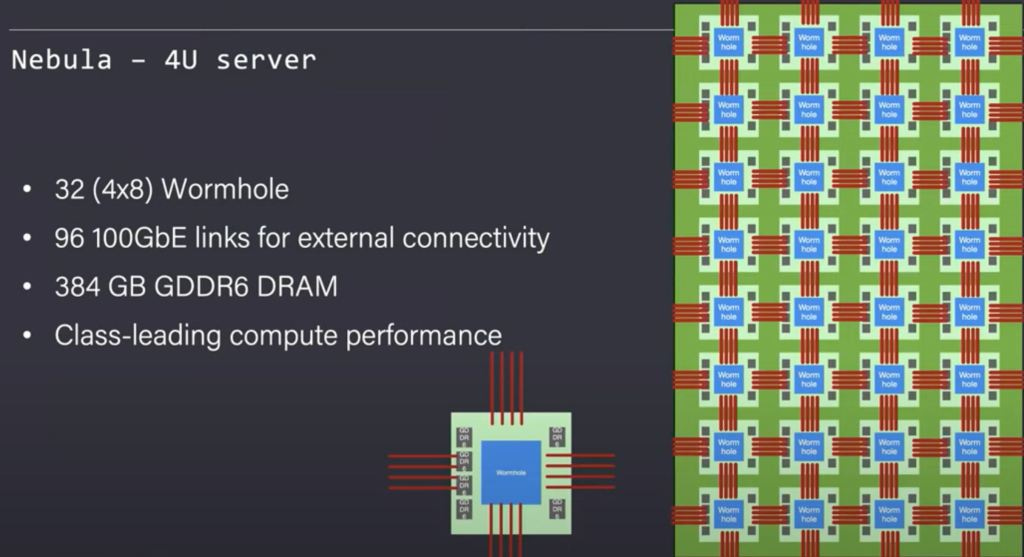
Tenstorrent has designed Nebula as a base building block. It is a 4U server chassis. Inside this 4U server, they were able to stuff 32 Wormhole chips. The chips are connected in a full mesh internally with the capability to easily extend this mesh far beyond the individual server in a transparent manner.
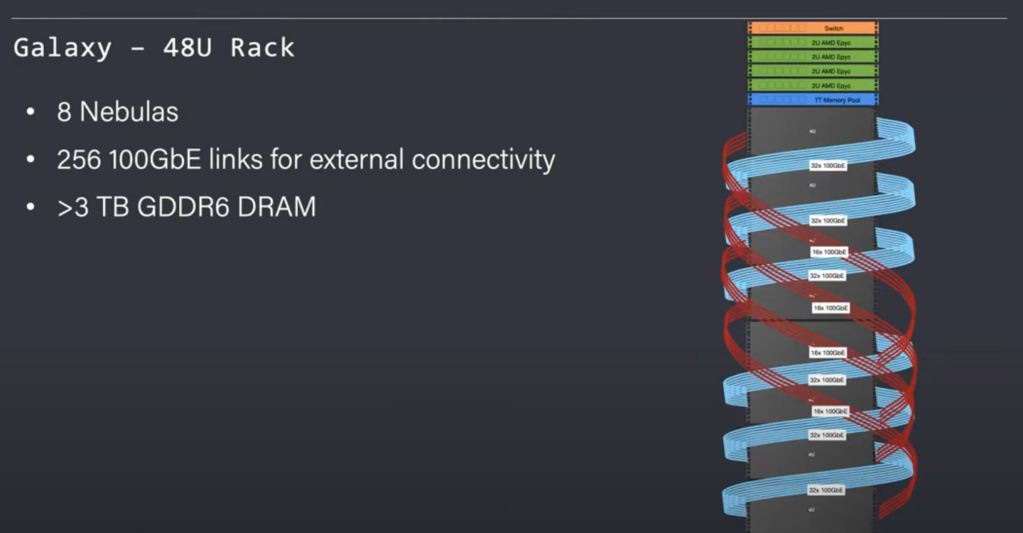
The fun does not stop there, Tenstorrent has shown off Galaxy. This is 8 Nebulas connected in an extended mesh. This rack also contains 4 AMD Epyc servers and a shared memory pool. The rack offers >3TBs of GDDR6 and 256Gb of external ethernet links. The general-purpose AMD Epyc servers and memory pool are connected to the ethernet mesh.
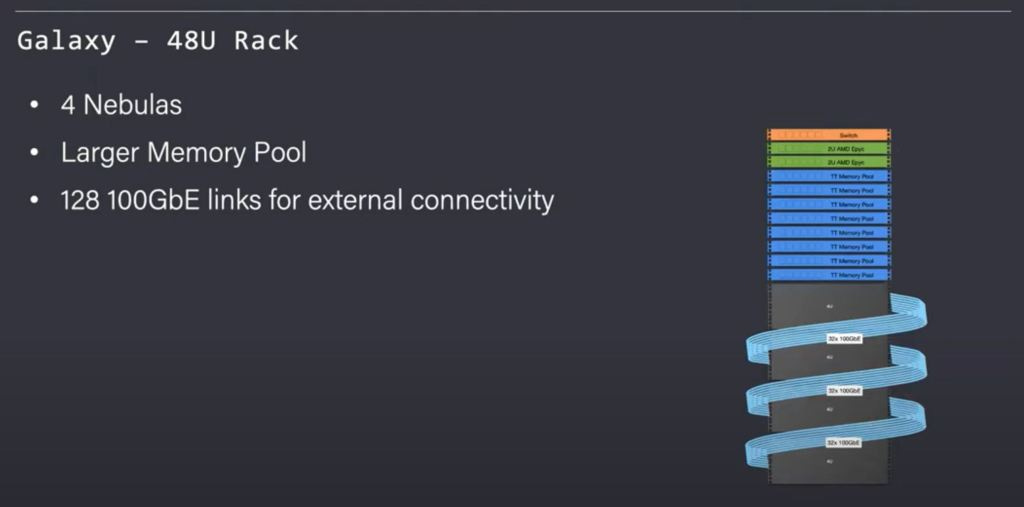
Tenstorrent recognizes that all AI workloads are not homogeneous. They offer a rack level server offering with half the Wormhole compute capabilities. The AMD Epyc server count is also dropped in half. This trade off of compute is made in return for a larger memory pool. 8x the memory is included per rack. This type of configuration would be better suited for models that are more memory intensive such as Deep Learning Recommendation Systems
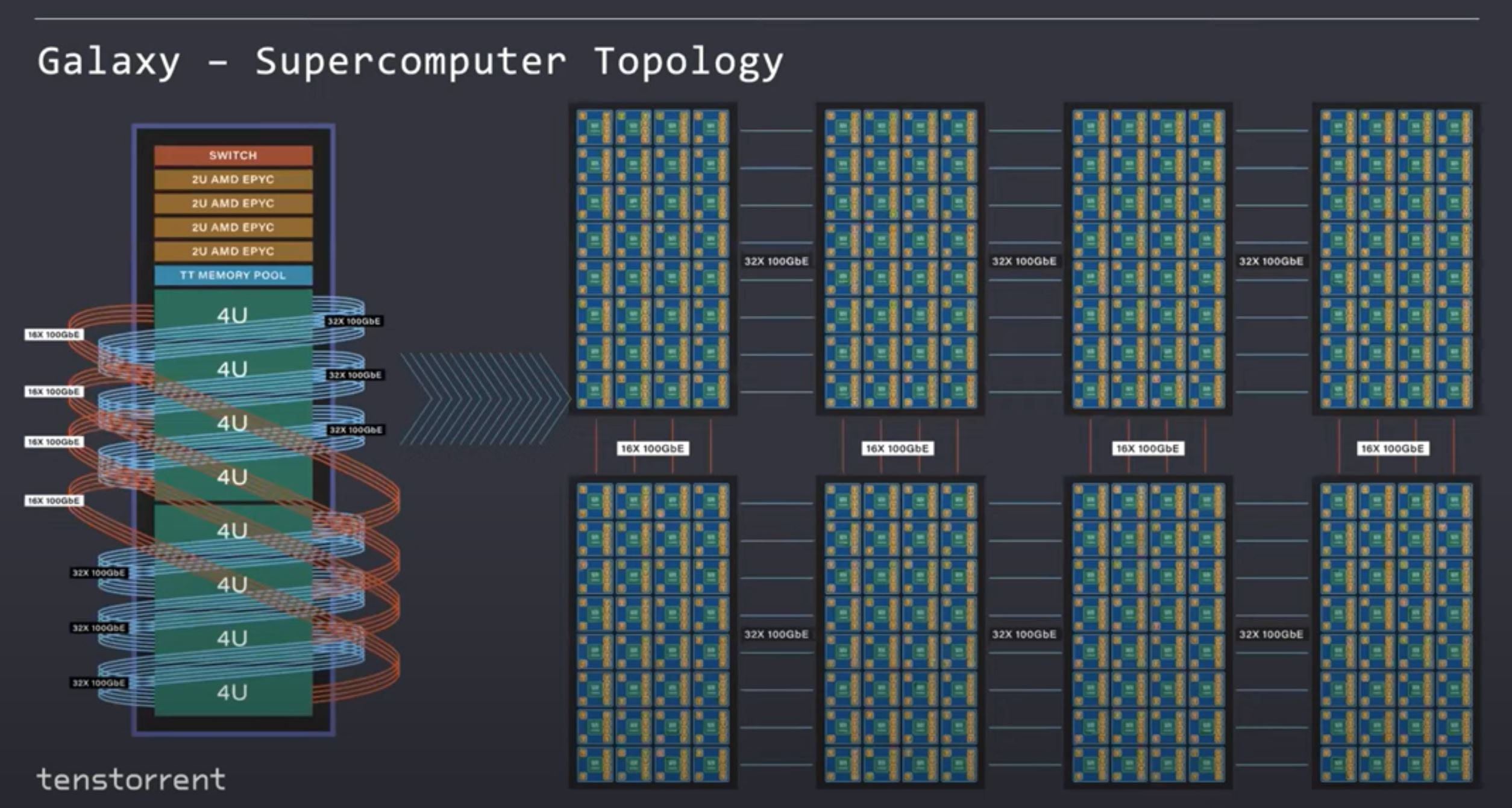
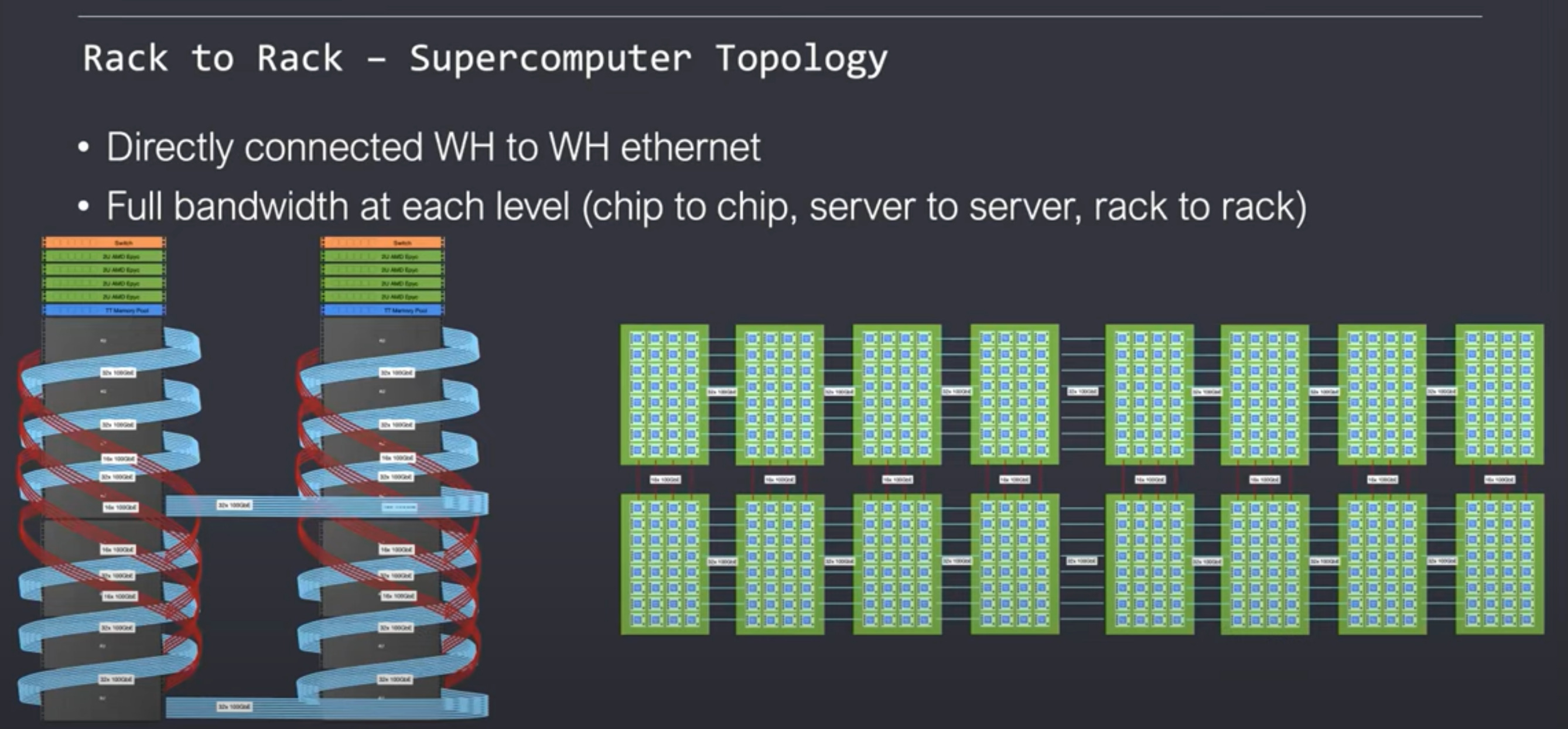
The scale out capabilities do not stop there. Tenstorrent supports rack units connected in a 2D mesh. The important thing about how they scale out is the way software handles it. To software, it looks like a large homogenous network of Tensix cores. The on-chip network scales up transparently to many racks of servers without any painful rewriting of software. Their mesh network can theoretically be extended to infinity with full and uniform bandwidth This topology does not require the use of many expensive ethernet switches because the Wormhole network on chip itself is a switch. The switch depicted on top of each server is only used for connecting these servers to the external world, not within the network. Nvidia solutions require the expensive Nvidia made switch to scale beyond 8 GPUs and beyond 16 requires the use of even more expensive InfiniBand networking cards and switches.
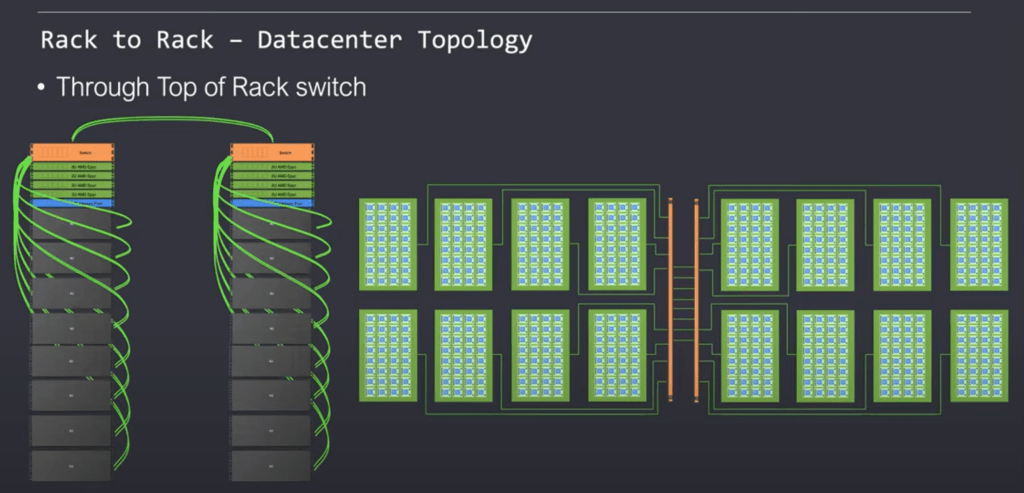
Tenstorrent supports multiple topologies. Each one has its own benefits and disadvantages. The classic leaf and spine models that is popular within many datacenters is fully supported. Despite the unequal networking capabilities, the on-chip NOC extends cleanly without breaking. Elasticity and a multitenant architecture are fully supported.

Wormhole does this by removing strict hierarchies. Scale out servers tend to have a hierarchy of intra-chip, inter-chip, inter-server, and inter-rack communications in bandwidth, latency, and programming hierarchy. Tenstorrent claims to have found a secret sauce that allows these different levels of latency and bandwidth to not matter for software. Despite this flexibility, chip utilization rates stay high. We are certainly skeptical how they can achieve this so cleanly.
Compiler and model designers spend a lot of time trying to figure out the scale out problem, and here is Tenstorrent, claiming they have the magic bullet. The compiler and researchers see an “infinite stream of cores.” They do not have to hand tune models to the network. Due to this, machine learning researchers are unshackled and scale models to trillions of parameters if need be. The size of the networks can easily be increased at a later date due to this flexibility.
This scale out problem is very difficult, especially for custom AI silicon. Even Nvidia, who leads the field in scale out hardware, forces the largest model developers to deal with these strict hierarchies of bandwidth, latency, and programming hierarchy. If Tenstorrent claim about automating this painful task is true, they have flipped the industry on its head.

To understand how they achieved this, we need to go back through the histroy of scale out training. Historically, for scaling up across CPU clusters, one would utilize a large batch size and split it across the cluster. There would be a central parameter server that aggregates the batches. This did not scale up well due to bandwidth limitations.
Next, GPU clusters with all reduce and higher levels of bandwidth between them led to further advancements. It still had limitations, and there were early attempts to combine other types of parallelism besides increasing batch size and sharding the data across the cluster.

The biggest limitations were that at some point you run out of batch size. The model will no longer converge and achieve high accuracy if you continue to increase batch size. With larger models, DRAM capacity becomes a constraint because the entire model is getting replicated across all nodes. Intermediate calculations even stopped fitting within the on die SRAM which required a large amount of DRAM bandwidth to store these intermediates. The resulting affect of higher DRAM size and bandwidth is that the cost of each node soars. This method of scaling worked fine for small models, but it quickly stopped being cost effective for larger models.

As larger models came into play, we started to see the emergence of libraries for efficient scaling. The user can now specify and combine model, pipeline, and sharded data parralelism across the cluster of servers. Essentially the user would split the model and layers of the network across nodes. This allowed the models to keep scaling because they did not need to replicate the entire model within each node. The biggest issue with this form of scaling is that it must be done manually. The researcher must choose what layers to map to what hardware and control the flow of data.
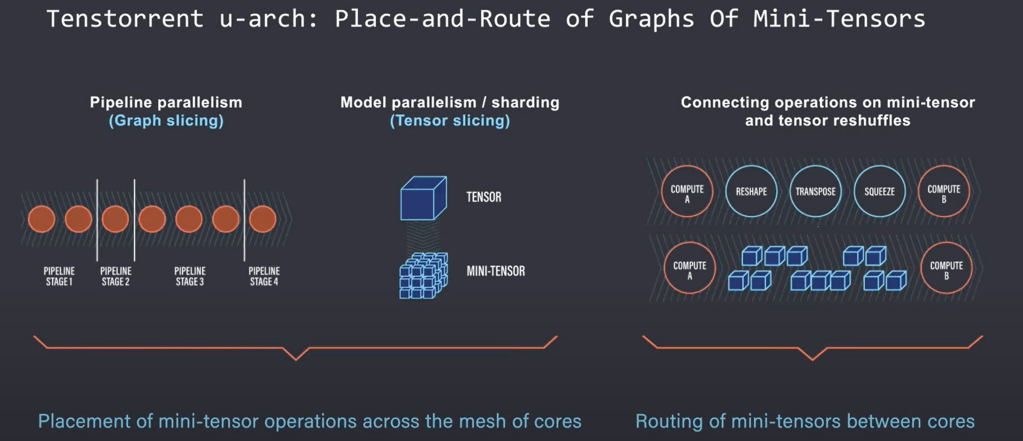
When scaling up a model you need to slice and map the model layers up across various nodes and hardware units. In addition to pipeline parallelism, individual tensor operations may also become too large for the individual tensor core hardware units to execute alone. These tensor operations within one node on a layer also need to be sliced into mini-tensors manually by the researcher.
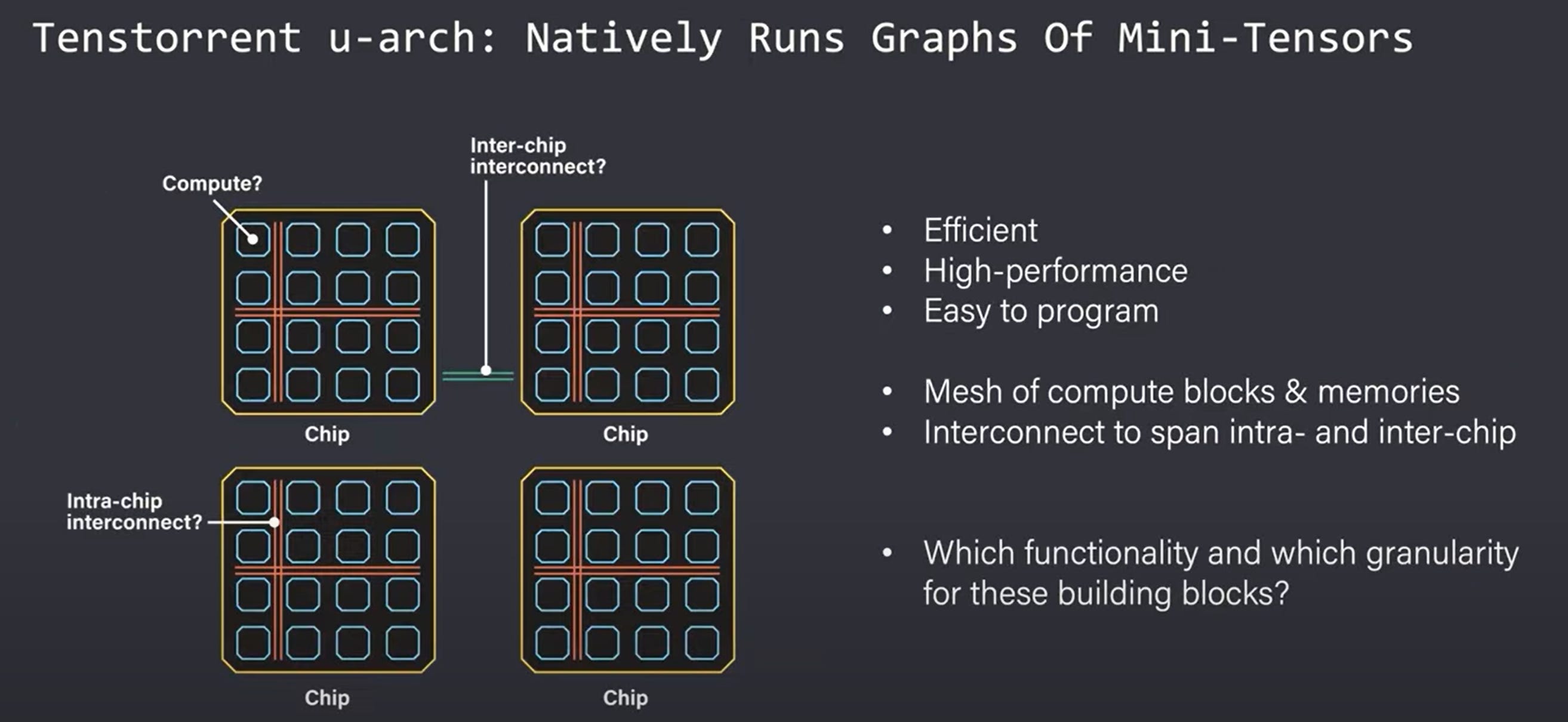
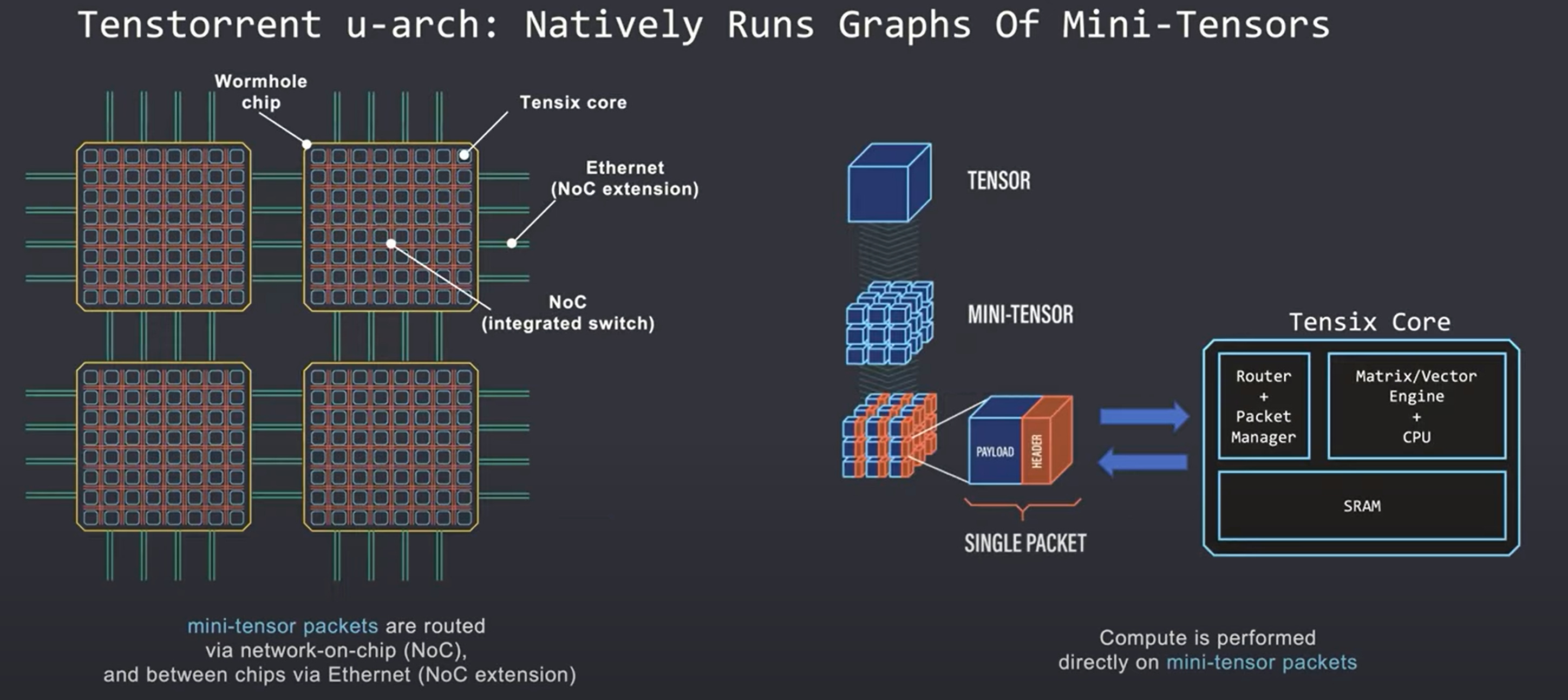
Tenstorrent goal was to create an architecture that can natively place, route, and execute the graphs of mini-tensor operations. Mini-tensors are realized as the native data type of the Tenstorrent architectures. This means researchers do not have to worry about tensor slicing. Each mini-tensor is treated as a single packet. These packets have a payload of data and a header that identifies and routes the packet within the mesh of cores. The compute is done directly on these mini-tensor packets by the Tensix core, each of which includes a router and packet manager as well as a large amount of SRAM. The router and packet manager deals with synchronization and sends computed packets to flow along the mesh interconnect whether it is on chip or off chip over ethernet.

From a software perspective, the transfer of packets looks uniform across the entire mesh of cores. Sending packets between cores on the same chip looks the same as sending packets between cores on different chips. Because each chip and the NOC itself acts like a switch, the mini-tensor packets can be routed along the mesh of cores to the core it needs to go to next.

There are 5 key primitives for mini-tensor packets. There is push/pop for moving packets between cores. Copy, gather, scatter, and shuffle are also available in unicast or multicast depending on the consumer or producer relationship within the graphs. You can manually compose the primitives together to build up a graph of mini-tensors natively. The easier route for most will be to use the compiler which can take PyTorch output. The complier will lower the output into a graph that is composed out of these primitives. This can then be run on the hardware with 0 overhead.
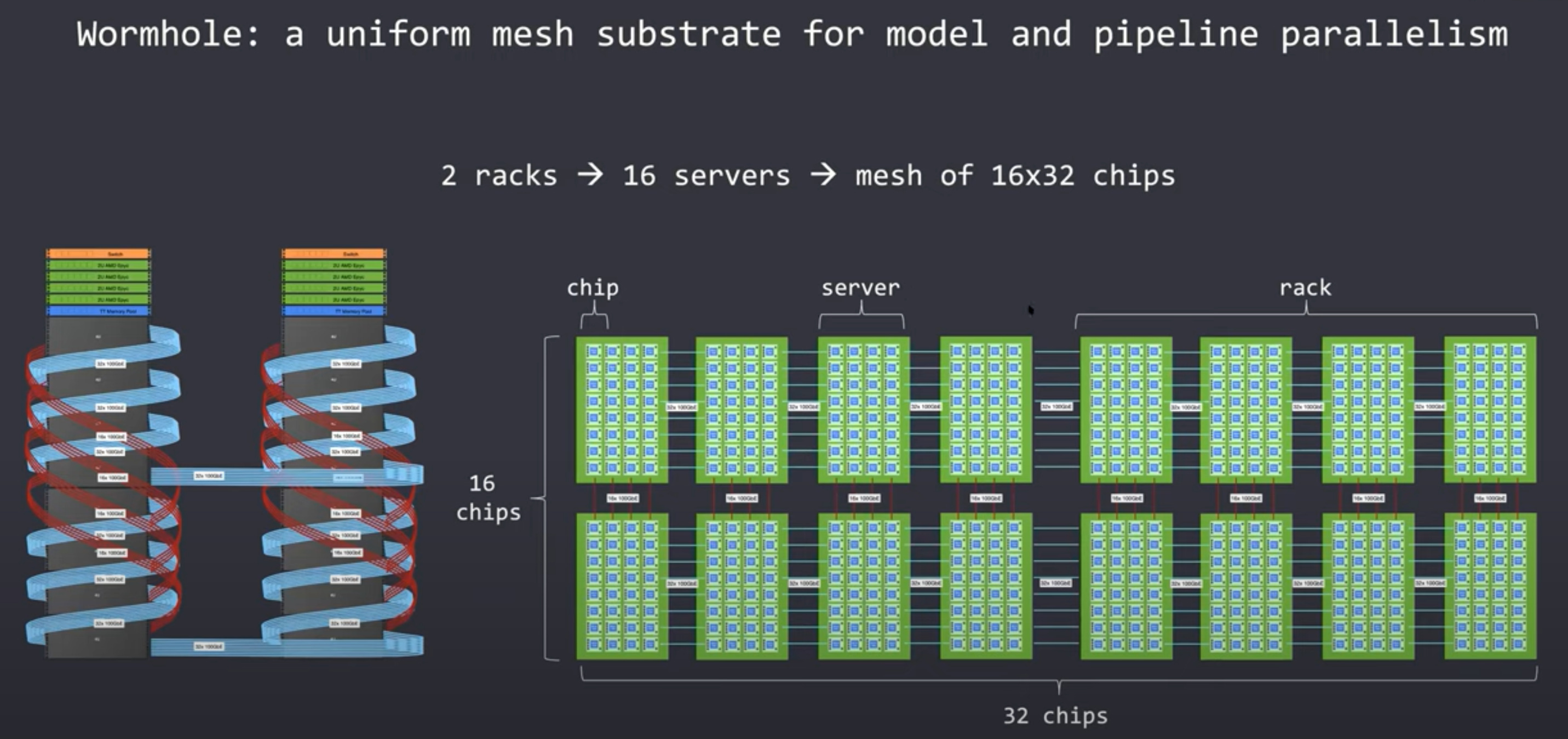
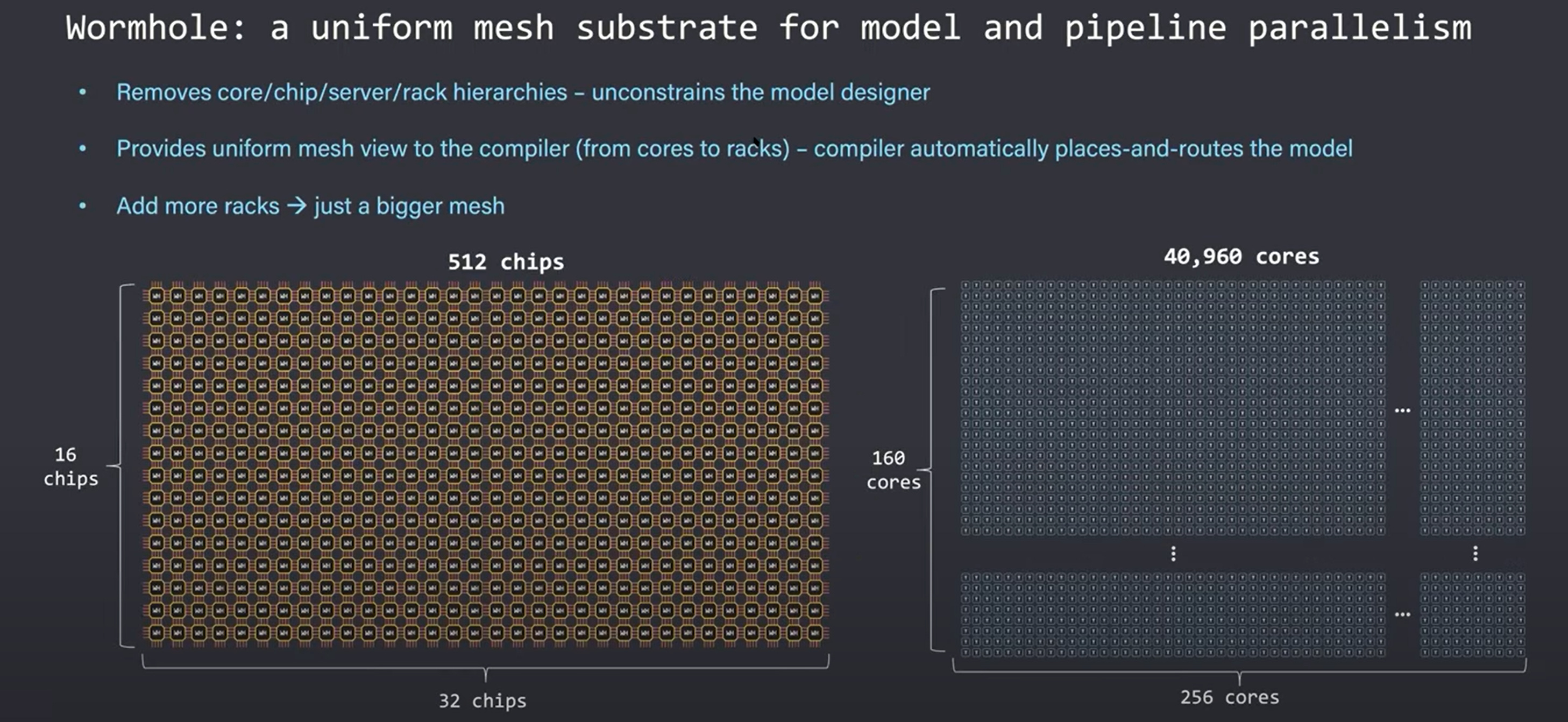
Despite containing many chips, servers, and racks of Wormhole chips, the software itself only sees this mesh of cores. The strict hierarchies are removed and that unconstraints the model developer. The compiler automatically places and routes the mini tensors efficiently across the network depending on the network topology rather than having the model developer worry about it. Adding more servers extends the mesh and allows the model to scale out without any worries.
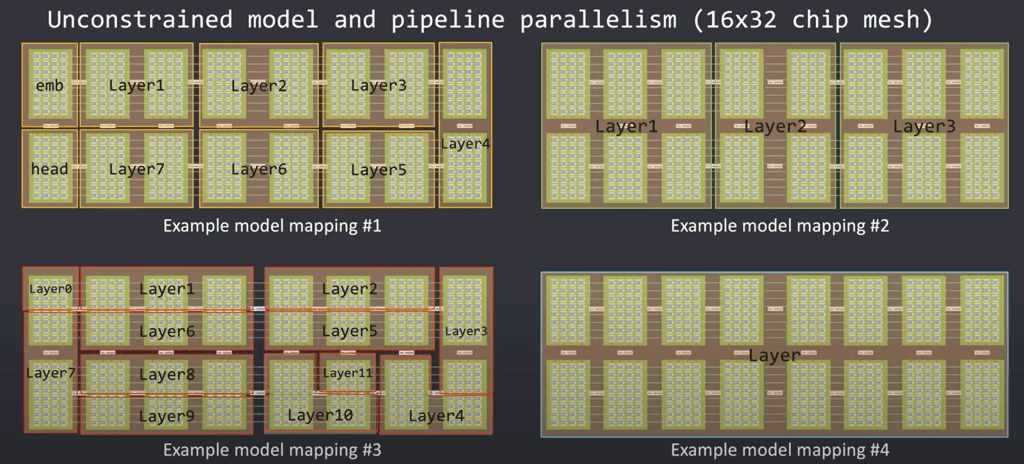
These boundaries allow large amounts of model pipeline parallelism. Layers within a network can use an arbitrary number of resources to match the compute needs. A layer that doesn’t need much compute can use half a server or half a chip, but another layer that need a lot of compute can stretch across racks. The 4th example shows that a single layer can even be stretched across racks of servers if your mesh is large enough. The compiler sees the size of the mesh and maps layers based on their size, whether the mesh of cores is 1 chip or the mesh of cores is 10,000 chips across many server racks.
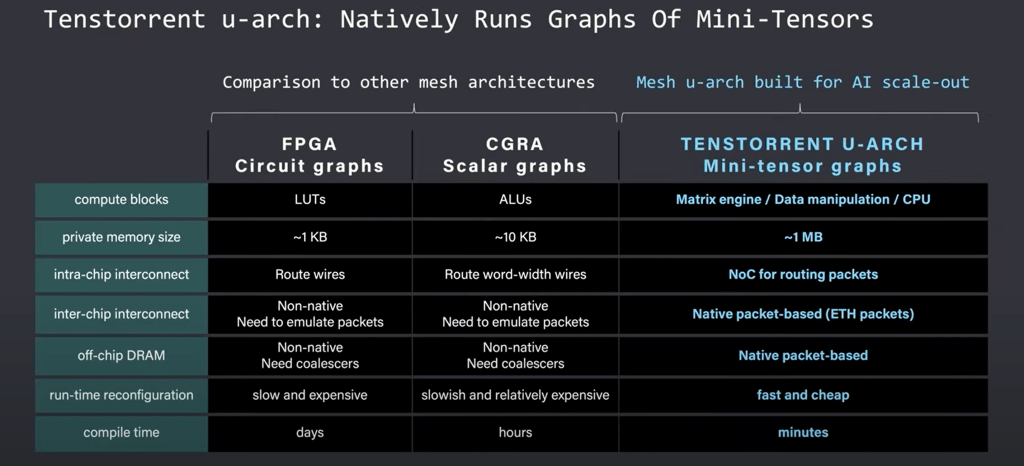
Compared to other mesh architectures, the Tenstorrent mesh is much larger and more scalable. FPGA’s are at the very fine level and require obscene amounts of time to hand tune. CGRA’s run scalar graphs, but they still have many limiting factors. Tenstorrent has multiple teraflops in their matrix engines and much larger memory sizes. The NOC, packet manager, and router intelligently take care of intra-chip and inter-chip communications leaving the model developer to focus on other pieces of the puzzle. This allows it to be more efficient for scale out AI workloads while also being much easier to develop on.

Tenstorrent has achieved something truly magical if their claims pan out. Their powerful Wormhole chip can scale out to many chips, servers, and racks through integrated ethernet ports without any software overhead. The compiler sees an infinite mesh of cores without any strict hierarchies. This allows model developers to not worry about graph slicing or tensor slicing in scale out training for massive machine learning models.
Nvidia, the leader in AI hardware and software has not come close to solving this problem. They provide libraries, SKDs, and help with optimization, but their compiler can't do this automatically. We are skeptical the Tenstorrent compiler perfectly can place and route layers within the AI network to the mesh of cores while avoiding network congestion or bottlenecks. These types of bottlenecks are common within mesh networks. If they have truly solved the scale out AI problem with no software overhead, then all AI training hardware is in for a rough wakeup call. Every researcher working on massive models will flock to Tenstorrent Wormhole and future hardware rapidly due to dramatic jump in ease of use.
This article was originally published on SemiAnalysis on June 25th 2021.
Clients and employees of SemiAnalysis may hold positions in companies referenced in this article.
Very interesting, thank you. Always a good idea to keep an eye on what Keller is doing. Was curious about this for a while, thanks for breaking some of it down.