


Tenstorrent Blackhole, Grendel, And Buda - A Scale Out Architecture For Sparsity, Conditional Execution, And Dynamic Routing
Tenstorrent Blackhole, Grendel, And Buda - A Scale Out Architecture For Sparsity, Conditional Execution, And Dynamic Routing

Tenstorrent is one of the leading AI startups with one of the most interesting architectures and software stacks. They have incredible hype behind them partially due to their CTO being the legendary Jim Keller, but also because they think about the problem of AI in a unique way. Most AI startups are flailing with software while delivering hardware that is even in the best scenarios barely better than Nvidia’s. All the while they ignore how neural network and AI model architectures are evolving. Tenstorrent at the very least is flipping this on its head. They have made some very large claims about the future of neural network model architectures, issues with edge versus datacenter, hardware performance / efficiency, and software prowess. In addition, much of what Tenstorrent said ties directly into what Google shared on their 540 billion parameter PaLM model
We recommend you check out our prior piece from last year on Tenstorrent’s hardware, system, and software architecture. In it we discussed the evolution of the TenSix core, Jawbridge, GraySkull, and Wormhole chip architectures. We also discussed the Nebula and Galaxy system level design and the software architecture that runs graphs of mini-tensors. The unique hardware and software allow for unconstrained model and pipeline parallelism without any strict hierarchies.
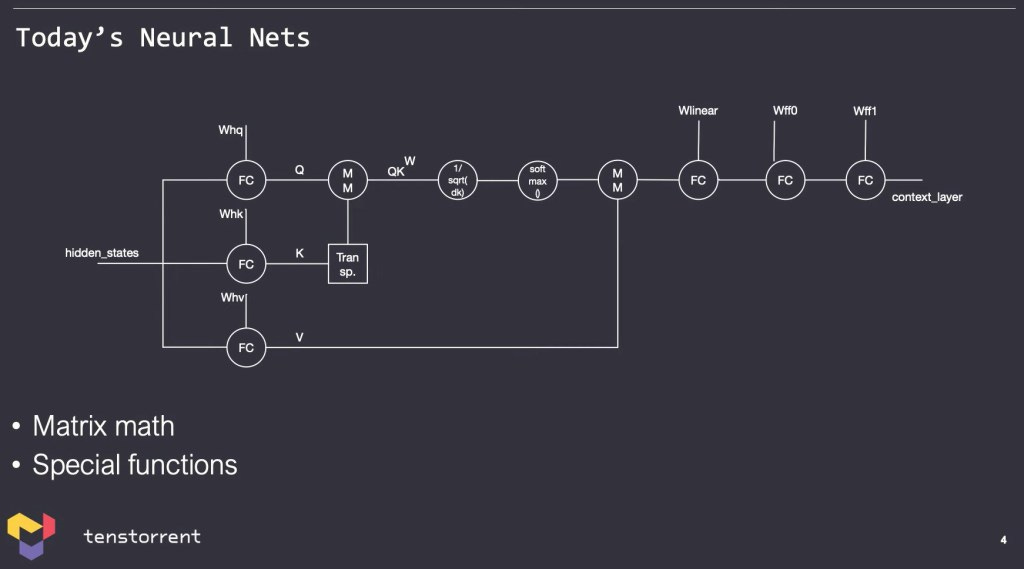
First let’s talk about the current generation of neural networks which are swinging to larger and wider models, with huge dense matrix multiplies, such as multi-layer perceptron networks. There are a lot of matrix multiplies which include learnable parameters and matrix multiples that include non-learnable parameters. There will be some simple transformations such as a SoftMax Function, but for the most part, the main limiting factor is tons of matrix multiplies.
Models have generally evolved to take advantage of GPU hardware and GPUs have evolved to accelerate those models the general community is developing. As such a feedback loop has been created in which model architecture is developing towards a (potential) local maxima that works best on the architecture type of a GPU. Large matrices and high batch sizes hare seen as the hammer to solve every scaling issue to allow model sizes to continue to scale exponentially.
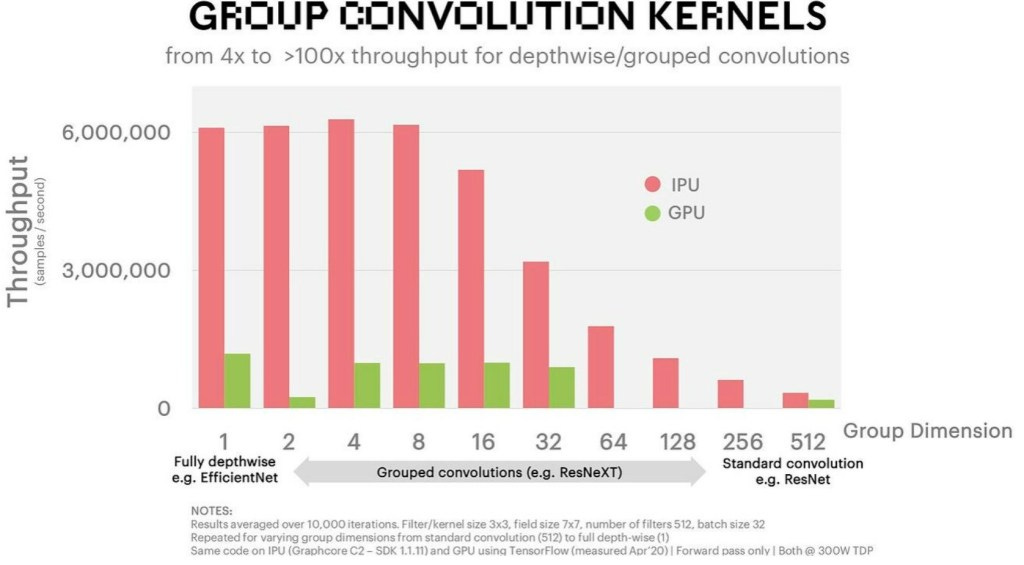
Any Nvidia competitor’s architecture which doesn’t focus on these has been getting left in the dust. For example, Graphcore has an architecture that works excellently on grouped convolutions. Their hardware can train at really low batch sizes as well as with smaller matrix sizes without murdering their utilization rates, but that doesn’t really matter because most models under research or used in production use a different model architecture with larger matrices and batch sizes.
It’s a vicious cycle that is not going well for AI startups.
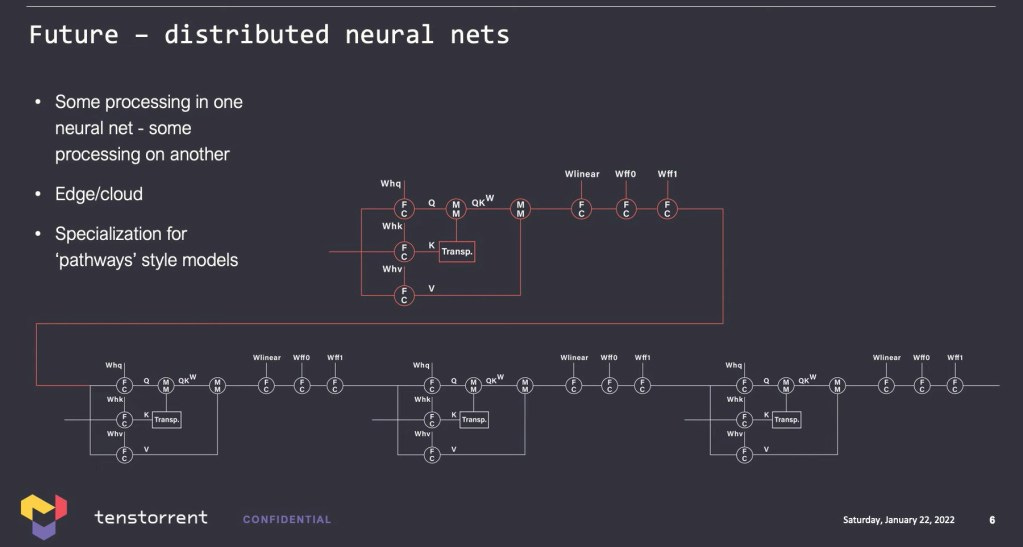
Tenstorrent believes changes are coming to neural networks. Rather than the path of the current path that large transformer models are taking us down, they believe models will become more conditional with some mixture of the current paradigm, but also with programmatic functionality such as sorting embedded which requires more heterogeneous compute beyond just matrix multiplies. They also believe models will evolve to have more runtime conditional routing where the result of a portion of the model will change which subsequent layer the model will be fed to.
These models with more conditional routing will probably be good for GPUs because they execute layers sequentially in time and can easily change the layer ordering, do loops, or any other conditionals. Many issues with GPUs can be solved by increasing batch sizes. Pipelined architectures like that of many AI startups, may have a much harder time doing conditional routing without sacrificing performance. These startups tend to compile a network and place them in a particular pattern on the die. Tenstorrent could have an advantage with fine grained routing of different parts of the model. More SRAM on die would be needed for these operations and Nvidia’s GPUs do not generally have huge SRAM pools.
Conditional routing is still nascent in its research and use today, but Tenstorrent envisions a future where a single, very large, highly effective, but incredibly computationally expensive neural network is built. This model would run in the datacenter. At the edge, cameras or sensors would have a segment of the neural network that does some pre-processing and naturally interfaces with the rest of this model. They compared this type of architecture to that of the human or animal where the eyes and appendages have neurons themselves, but the brain is the central hub.
The world is going to go to 80, 90% of all cycles, are going to be AI cycles running on AI processors programmed by data.
Jim Keller, CTO of Tenstorrent
Tenstorrent offered an example in smart retail of heterogeneous compute being required for a model. There could be a video decode in stage, some model processing, database read and write, further model processing, followed by video encoding. It’s quite interesting that Tenstorrent offered this example as the only single chip solutions that can offer this today are Intel client/edge CPUs, Nvidia GPUs, and AMD/Intel FPGAs.
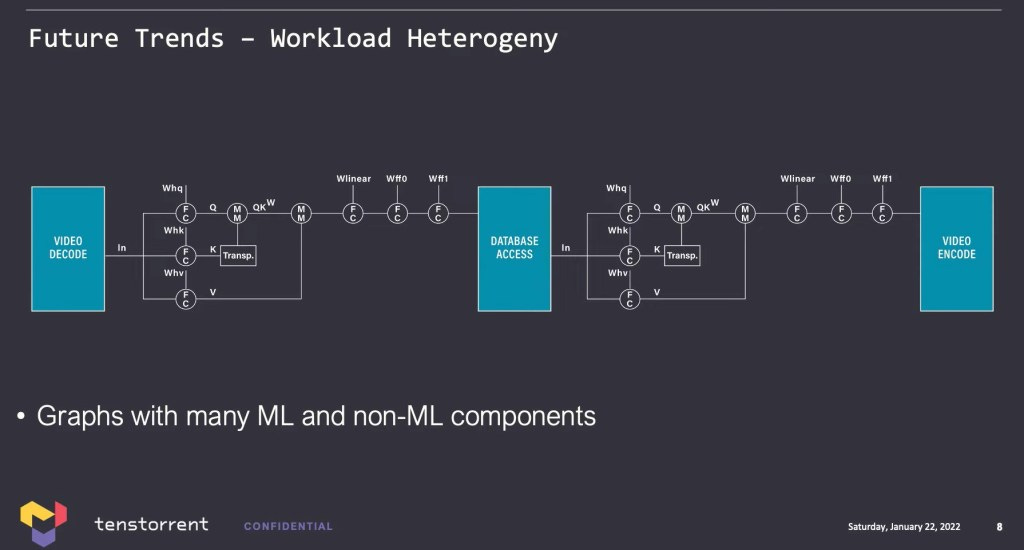
Tenstorrent also made a very bold claim that there shouldn’t be datacenter machine learning companies or edge machine learning companies, but instead what’s needed are end-to-end machine learning companies. Tenstorrent believes there are strong compatibility dynamics between training future looking neural networks and running the inference for them. They believe architecture specific features will crop up that allow for 10x faster training that must be maintained when these models are deployed in the edge. They believe any successful architecture must be able to scale from the 100 milliwatts to megawatts. We are unsure what Tenstorrent’s strategy is for getting into these low power areas, such as smartphones and embedded.
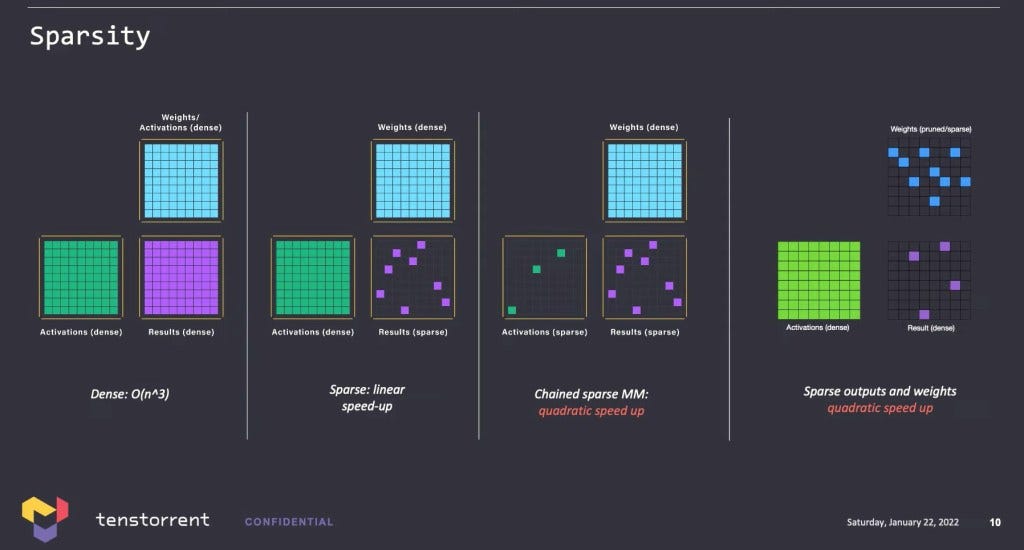
With regards to model sizes, Tenstorrent came out very strongly against the trend of model size growth. They believe that a neural network size cannot grow again like GPT3, which was 1,000x larger than GPT2, due to the costs of a single training run being on the order of $10’s of millions of dollars. We believe these cost estimates are too large as even a much larger model like DeepMind’s Chinchilla likely cost around $10 million.
Tenstorrent are big believers that unconditional sparsity, conditional execution, and dynamic routing can allow for massive decreases in the amount of computation as entire blocks of a large model can be skipped. In any multiply, if there are 0’s, there is no point in going through with the calculation as you already know the result. Structured sparsity, where the locations of these 0’s is known, is already implemented in Nvidia and others hardware. Tenstorrent wants to take this to the next level. They also want to be able to execute portions of the network conditionally and dynamically route through these portions of the network which are relevant if certain conditions are met.
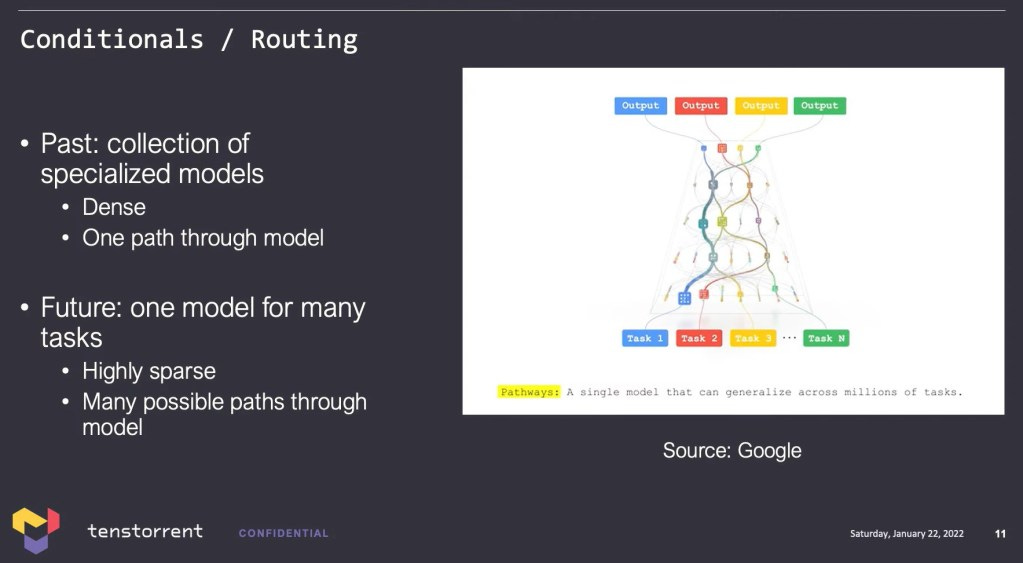
The inspiration behind this is yet again the human brain. Only a portion of the brain’s neurons are active depending on the task at hand. Experiments conducted under an MRI will show that you use your entire brain across a variety of tasks, but only certain areas will be lit up depending on the exact task. Biologically, humans are great at sparsity, conditional execution, and dynamic routing.
This leads back to Tenstorrent’s vision of a single, very large, highly effective, but incredibly computationally expensive neural network. They are hardly alone in this vision as Google has already shown they are steaming down this path. Recently they disclosed the PaLM model which was trained on the biggest configuration of their in-house TPU’s ever, 6,144 chips across two TPUv4 Pods.

Google challenged the core belief that training bigger and bigger models is wasteful. The study’s results reiterate that larger models have more efficient sampling than smaller models because they apply transfer learning better.1 Through the usage of “Pathways,” a single AI model can be generalized across many tasks and learn them faster than a singular model.
Just like the human mind picks up tasks incredibly quickly because it is generalized to so many others, the same applies to neural networks. Instead of using the entire network for solving a problem, a pathway can route its tasks through a portion of that model to keep it energy and data efficient on inference.
Tenstorrent wants to create hardware that runs huge models that can take a large number of varying tasks and apply them to various criteria and train itself in a highly spare manner where a given input has a unique path through sparsity within the matrix or routing.
We started Tenstorrent about 5 years ago with exactly these ideas in mind. We wanted a computer that can scale from a tiny little sub-watt deployment to a data center size deployment and be targeted by the same compiler stack, same software stack. We wanted a computer that can enable artificial neural nets to do what our brains do. Meaning turn on only two percent of the model for any given input training or inference.
Ljubisa Bajic, CEO of Tenstorrent
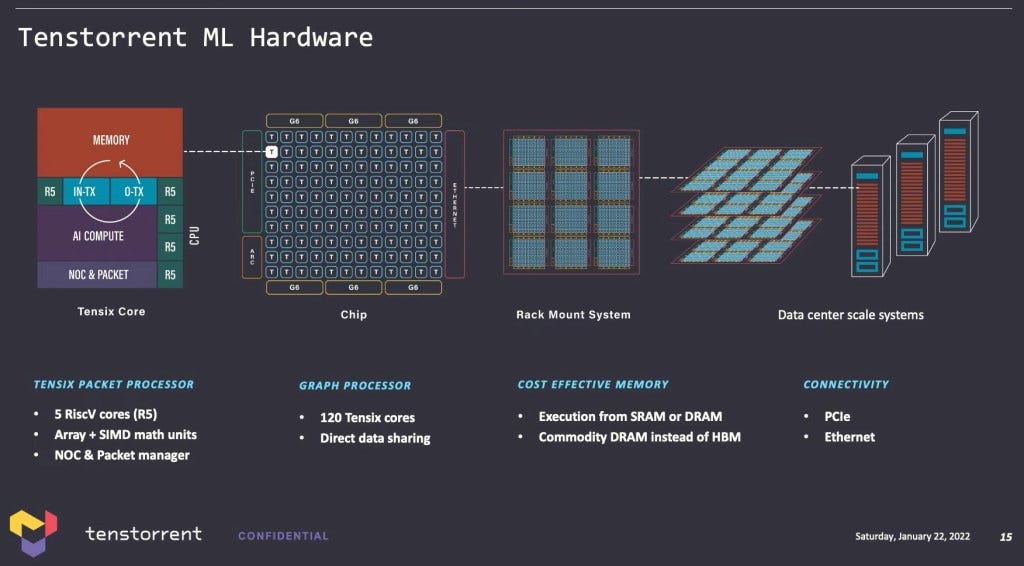
We explained Tenstorrent’s hardware in detail last year in this article, but as a summary, here is their strategy. Tenstorrent utilizes commodity LPDDR or GDDR memory rather than HBM to maximize dollars spent on compute while keeping bandwidth and efficiency high. “TenSix” is an array of RISC-V cores alongside a packet manager. This inputs packets of mini-tensors from the network on chip onto the local SRAM and converts data types. The RISC-V cores then process the data. The package manager repacketizes them and push them on through the network on chip (NOC) to the next destination TenSix core. This network extends to many TenSix cores across their NOC and this NOC can be extended across chips with the on-die ethernet switch. Tenstorrent can theoretically scale infinitely to across to thousands of systems without software issues as the sea of compute will still act transparently as a large mesh of TenSix cores.

We did a deep dive into the predecessor, Jawbridge, as well as Grayskull, and Wormhole in our article last year. Grayskull is the second-generation chip and is built on GlobalFoundries 12nm. Tenstorrent claims this chip is the same performance as Nvidia’s A100 GPU with twice the density and slightly lower power. We have heard from a large hyperscaler that evaluated Grayskull, that it’s a decent bit slower than Nvidia’s 4.5-year-old V100.
Tenstorrent says that they will have over 1,000 dual Grayskull chip cards by the end of the year installed in datacenters. Tenstorrent also claims that in Q1 of 2022, they will have a ~1,000 chip machine of Wormhole installed in a datacenter.
The new hardware disclosures are with Blackhole on TSMC 6nm and Grendel on TSMC 4nm. Blackhole increases compute heavily, adds 24 RISC-V CPU cores licensed from SiFive, and upgrades the 16x100G ethernet to 12x400G ethernet. Blackhole also moves the memory from GDDR6 to DDR5. This chip is supposed to tape out this year.
The Grendel chip will increase compute further and move up to 64 RISC-V CPU cores. These will be an in-house design as SiFive cores are not as performant as what they can develop internally. Jim Keller during the talk specifically described the prior generation SiFive core as “not bad.” The ethernet switching capabilities will be expanded again to 16x400G. This chip is supposed to be “around a year after Blackhole.” This indicates a 2023 tape out date.
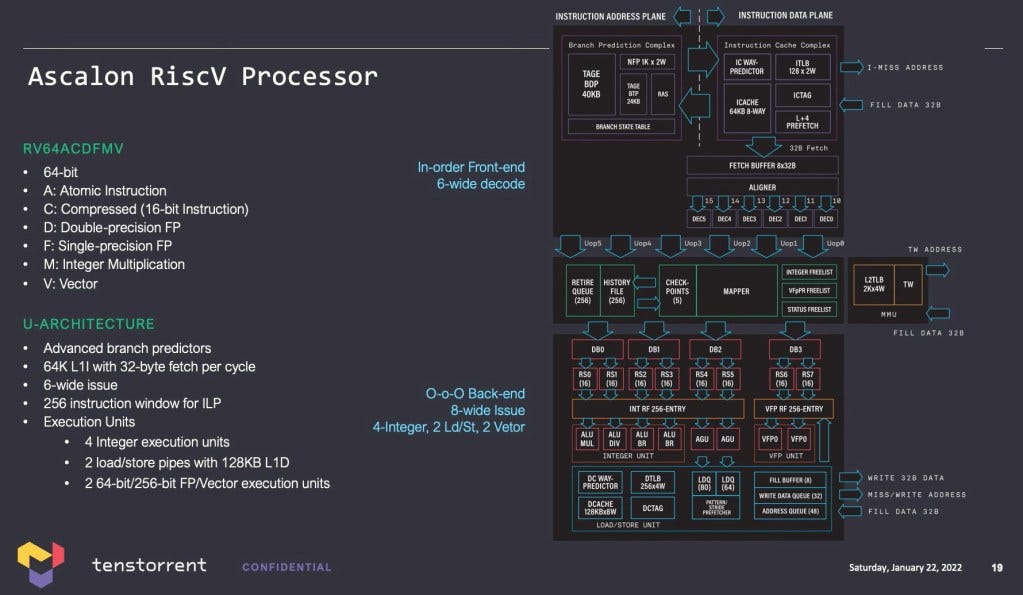
Testorrent’s in-house core is a 64-bit out of order and it’s fairly-wide with its two 256-bit vector units. They commented it is about the same level of performance as Apple’s old Cyclone core. The core itself is 1.2mm2. The team building it is mostly from Apple, AMD, Arm, Nvidia, and Intel. Tenstorrent talked about the verification process which they claim is quite unique. They have a reference model of the core and a performance model running the architecture to the performance model and block diagram. They claim this allows them to test and do verification at an earlier point in the process.
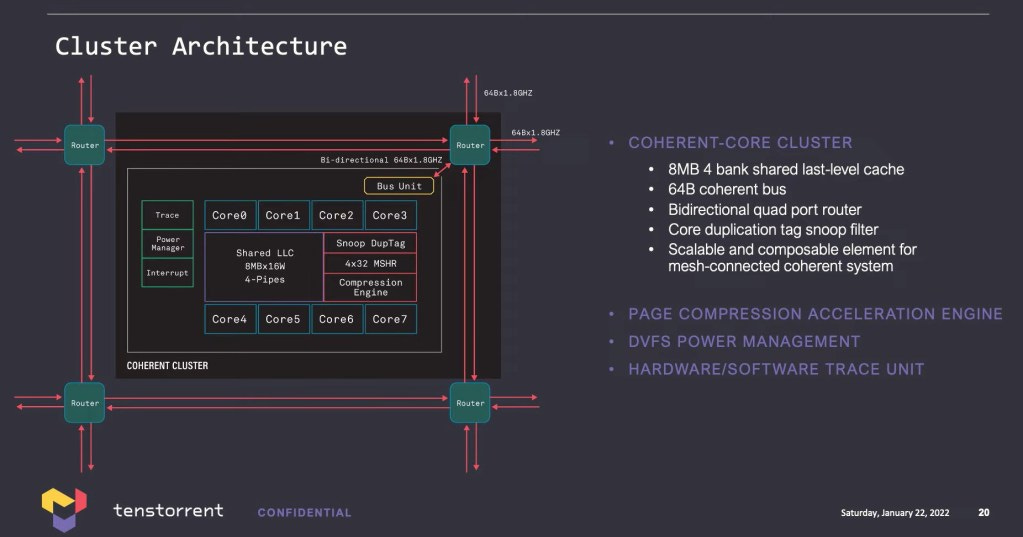
The core will be clustered in groups of 8 with 8MB of L2 cache shared across them. The router system will be identical to that on the TenSix AI processors, so the CPU cores can be integrated directly onto the fabric. This keeps the CPU core cache coherent to the memory controllers and AI processors. The biggest advantage to this is that they do not have to deal with a complicated driver model where the GPU writes to shared memory on a host and deal with interrupts with the CPU. The latency should be much lower as well.
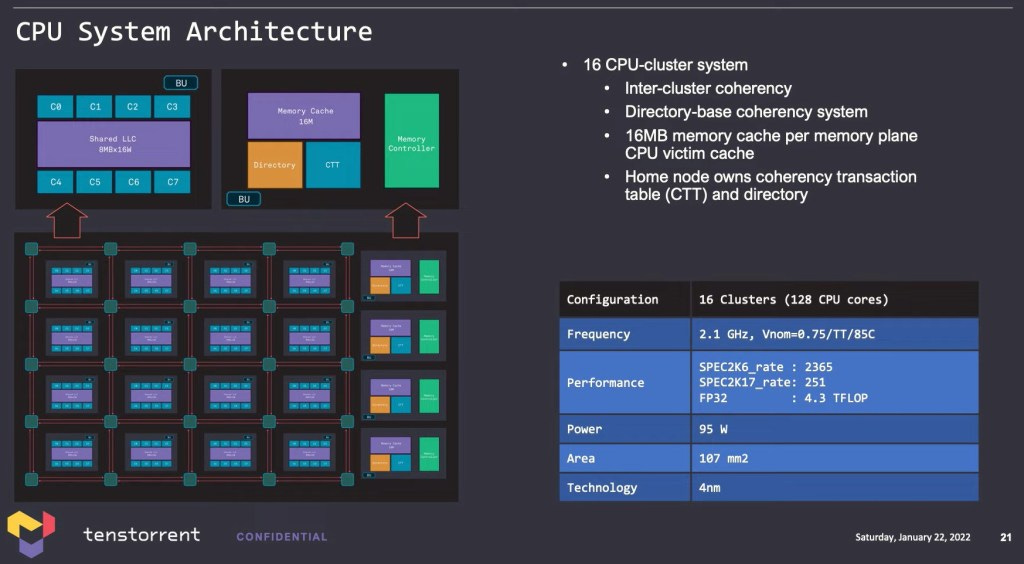
The purpose of these CPU cores will extend from using them for heterogeneous compute within more advanced AI models, network acceleration, storage acceleration, and allowing them to scale to arbitrarily numbers of Grendel servers. Tenstorrent suggested they may even license this core out in the future for others to use.
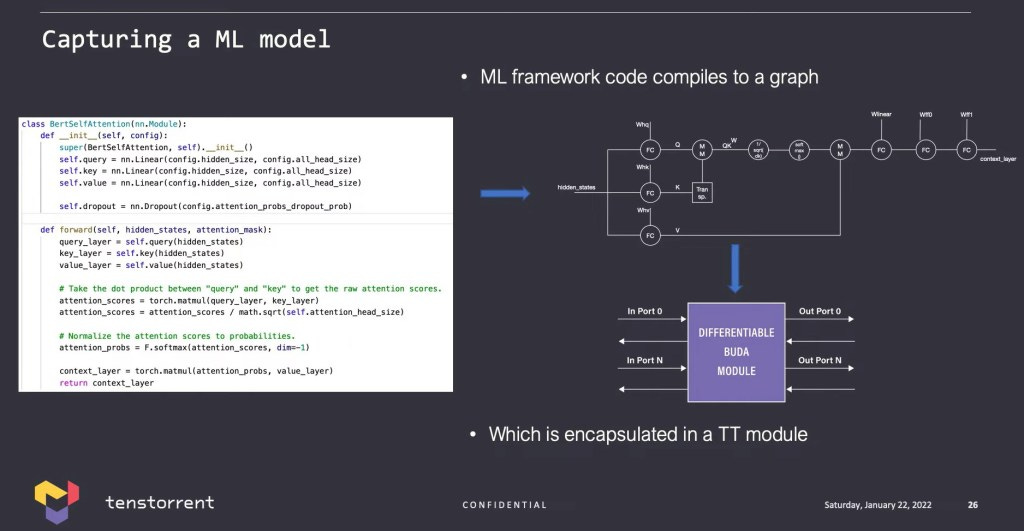
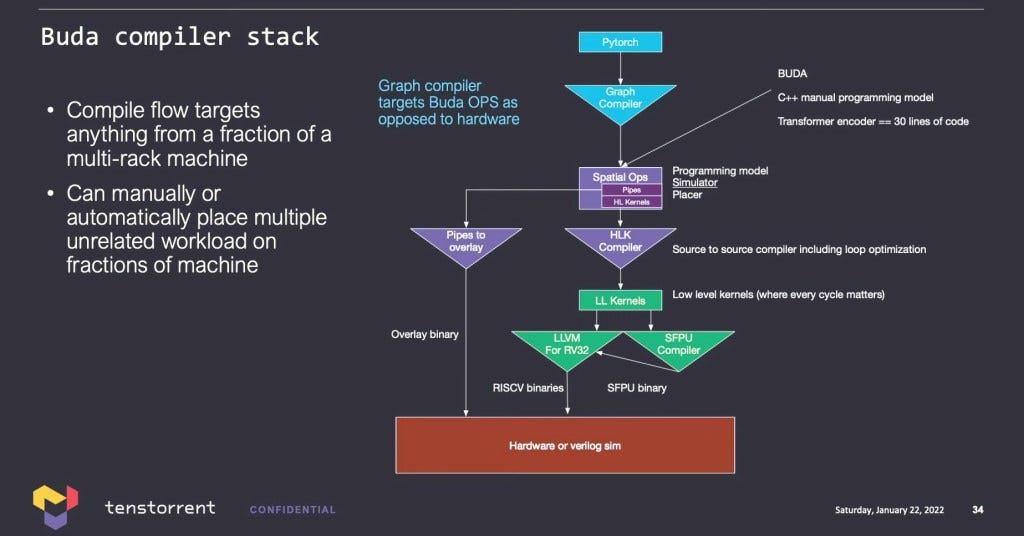
Tenstorrent has named their software platform Buda. It is a clear play on Nvidia’s software stack known as CUDA. Buda is compatible with only Pytorch. The module then allows you to either automatically or manually place a model onto a machine that can extend from a single chip to thousands within the same python interpreter.
There are commands to connect each module and provide it a source point and sync point to connect them. Synchronization is built-in and the connection will work for back propagation for training or for forward passes in inference. Tenstorrent claims it is easier to use than various MPI derivatives and Nvidia’s NCCL for collective communication.
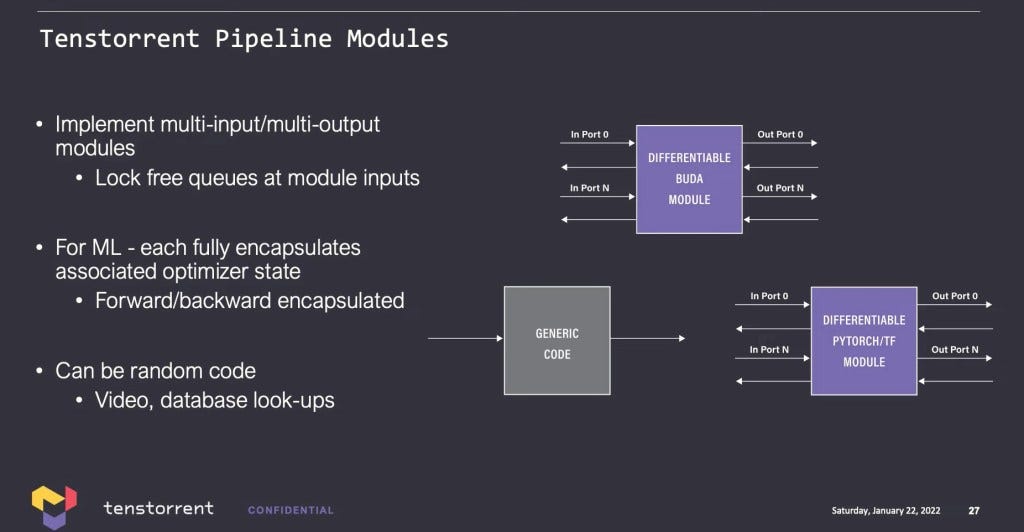
Tenstorrent’s software is agnostic to CPU, so it can be an Intel host, AMD host, or their own CPU core clusters which will be integrated in the future generations. They support modules with other frameworks including generic python code or even executables. For example, a C program can be written to accept inputs through pipes and output data.
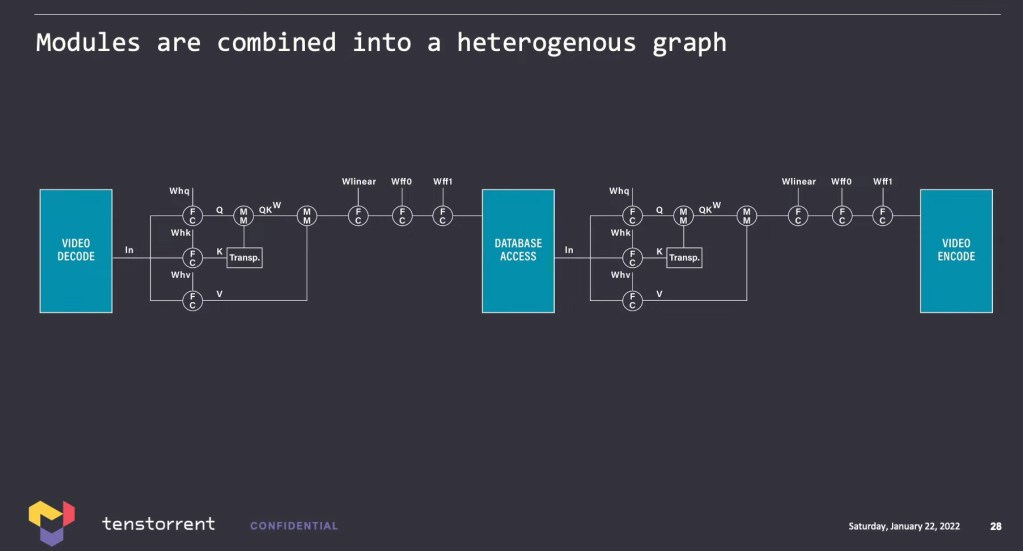
Video decode pipelines can be built in FFmpeg. Databases can be interfaced with as well. These features enable the heterogeneous compute that Tenstorrent envisions for the future of AI model architectures. With the addition of a very general-purpose CPU core on their extensible NOC and the ability to execute arbitrary code, the flexibility of their solution is immense.

Batch 1 operations are generally bottlenecked to memory access whether it is new data, or from one fully connected layer to the next. These operations generally need to run on the entire chip to be sped up, but they cannot be constantly waiting for data. GPUs can make short work of operations with large arrays of tensors due to their large matrix sizes. For operations with a small array of tensors, you become bottlenecked and must compensate with large batch sizes.

Any kind of pipelining across cores is going to make conditional computation a huge pain. Tenstorrent speaks about laying out operations or portions of the model on certain cores, chips, etc. If there are unused operations which are conditionally routed around, those cores sit idle and are wasted. We are unsure what Tenstorrent’s solution is for this case. GPUs use all their cores to execute one operation at a time, layer-by-layer. If a layer is conditionally skipped, it reduces the full amount of computation and speeds up the model.
Tenstorrent claims their hardware approach has a huge advantage to software. Other companies have to deal with a classical load store architecture for passing data, so they must spend a lot of effort manually writing kernels that fuse operations together. Tenstorrent says high quality fusing at the compiler level is still not really a thing. This necessitates that fusing must done.
That explains the large gap between some GPU vendors and other GPU venders in machine learning performance. Some of them have been hand fusing lots of kernels for a lot of things over the last five years or even more. Some haven't.
Ljubisa Bajic, CEO of Tenstorrent
It’s pretty clear Ljubisa is referring to Nvidia versus AMD here in a diplomatic way. They claim this can take teams of as many people as 2,000, which is not feasible for a startup which has forced them down the path they are on.
In the end, while the software story sounds nice, it is a big wait and see. The same applied to the hardware in fact. The claims about being designed for scale out from the ground up and beating Nvidia on perf are great, but they need to be materialized. The philosophy behind the company and their decisions in hardware and software are exciting, so we are hopeful. If this start-up shows real promise, we believe AMD should acquire them. AI and software chops are pretty much the only things AMD is still missing after their resurgence against Intel and acquisitions of Xilinx and Pensando.
We also encourage you to also check out our other AI chip coverage.
Qualcomm Hits a Homerun Cloud AI 100 – Powerful AI Inference For The Edge – Facebook was the hyperscale win we discussed in this article. They ended up pulling out due to software issues.
Graphcore Looks Like A Complete Failure In Machine Learning Training Performance
Tesla AI Day Supercomputer Chip Teaser | Is This The First Deployment Of TSMC InFO_SoW?
The Tesla Dojo Chip Is Impressive, But There Are Some Major Technical Issues
Also get subscribed as we will be doing a very deep dive on Nvidia’s Hopper architecture from the low-level functional units to the insane system level design.
Apa itu cto , stupied 😂 CTO adalah = CKF , yaitu code key forex , dalam program C = control , T = target , O = observalue ,, dalam sistem CTO adalah copy trust obyektifity , dalam teknologi CTO adalah = confirmasi turned other's 😅dalam artikel yang keluar dari seluruh program sistem teknologi , artikel nya menjadi CTO adalah colaborative teority obsure . Atau consider targeting oprasional .😅 Kemudian panel mengeluarkan contoh artikel CTO adalah , creativity teory original . Itu artinya yang bener . 😛