


Nvidia Ada Lovelace Leaked Specifications, Die Sizes, Architecture, Cost, And Performance Analysis
Nvidia Ada Lovelace Leaked Specifications, Die Sizes, Architecture, Cost, And Performance Analysis

Nvidia was the victim of a cyber-attack at the end of February where they were hacked for a vast sum of data. This hack was not only a disaster for Nvidia, but for all chip companies and the national security of all “western” countries. Among the hacked data was detailed specifications and simulation data for Nvidia’s next generation GPUs, Hopper and Ada. Hopper is now shipping and was unveiled by Nvidia at GTC. The specs matched exactly to this leak, but Ada, named after Ada Lovelace, is still many months away.
Ada, the next generation of client and video professional GPUs will be the topic of this article. Based on leaked specifications and simulations, SemiAnalysis and Locuza have teamed up to analyze the architecture, die sizes of various chips, and do a cost analysis on the GPU ASICs. SemiAnalysis and Locuza did not download any of the leaked files from the LAPSUS$ hack, however many people online shared excerpts.
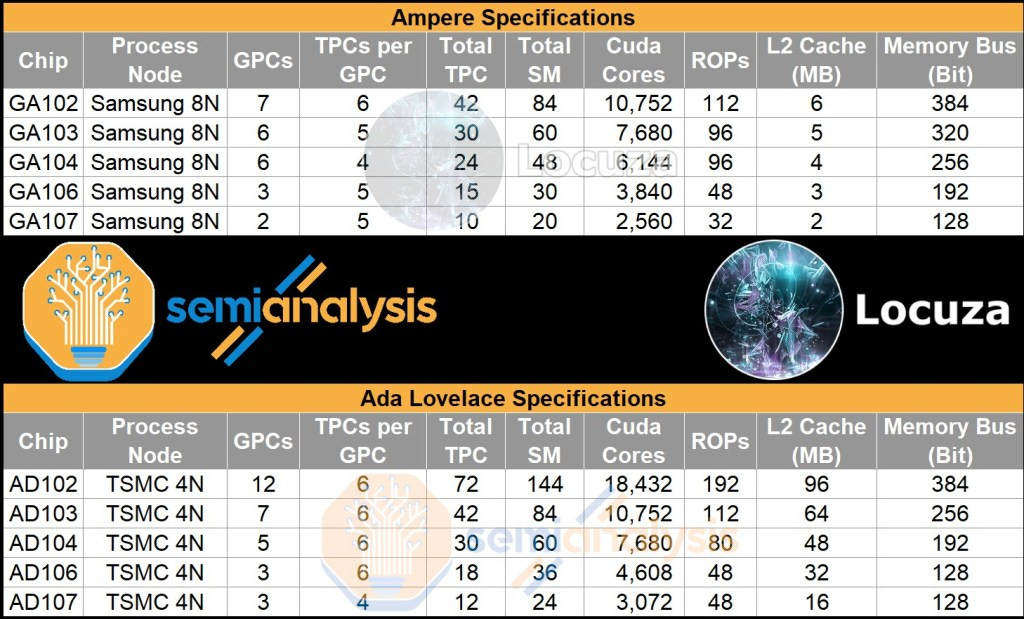
Based on these excerpts from the leak, we were able to extract the following specifications for Nvidia’s next generation Ada Lovelace GPU lineup and compare them to the current generation Ampere GPU lineup. There is also a video associated with this article, so check that out if you don't want to read!
The rest of this article will show block diagrams of each chip, architecture analysis, estimated die sizes, how we arrived at these die sizes, as well as some cost and positioning analysis. Given both Locuza and SemiAnalysis are directly supported by our subscribers, we would appreciate it if you read the rest of this ad-free article, subscribed to the free newsletter, paid newsletter, or supported us financially!
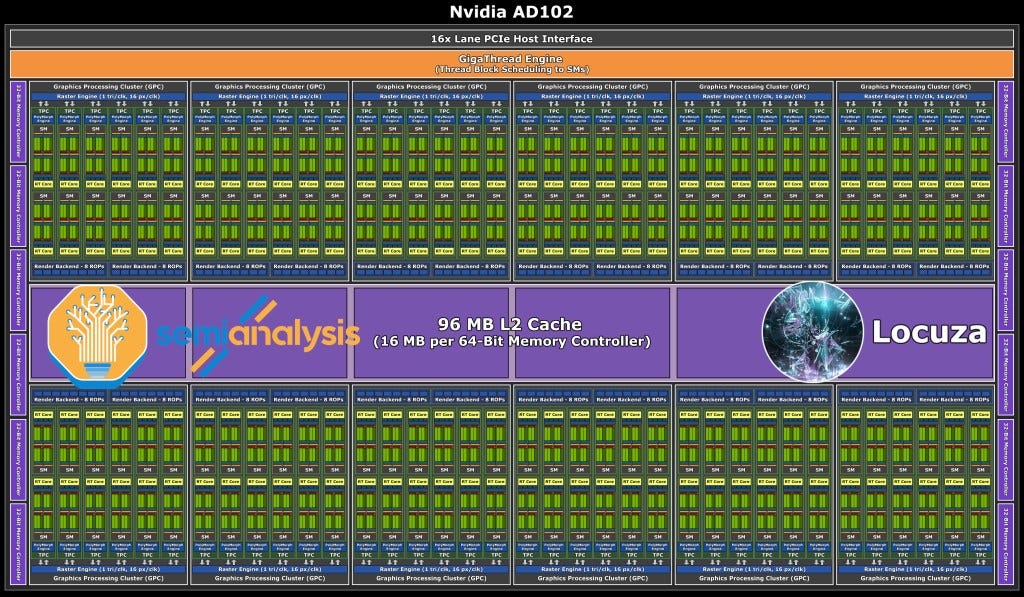
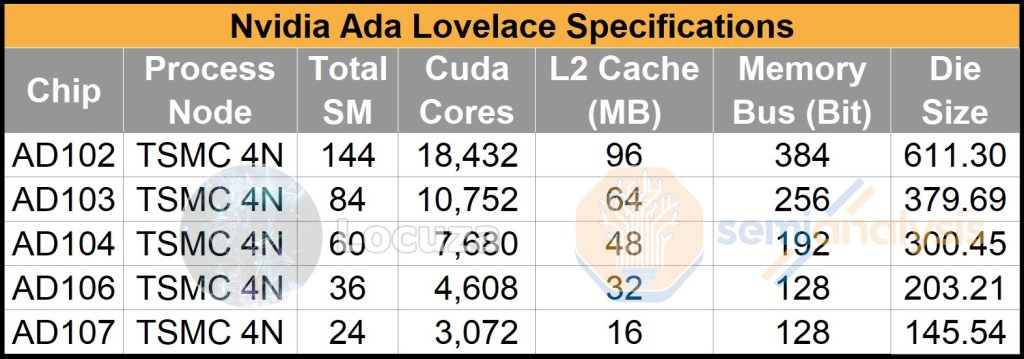
The top dog in the Ada architecture is AD102 estimated at ~611.3mm2. It’s a huge jump with over the previous generation GA102, with 70% more CUDA cores coming from 5 additional GPCs. The memory bus width remains the same at 384-bit, however we expect memory speeds to improve slightly to somewhere in the region of 21Gbps to 24Gbps. Despite the increase, this will not be enough to feed the beast. AD102 has 96MB of L2 Cache, far above the last generation GA102’s 6MB of L2 Cache.
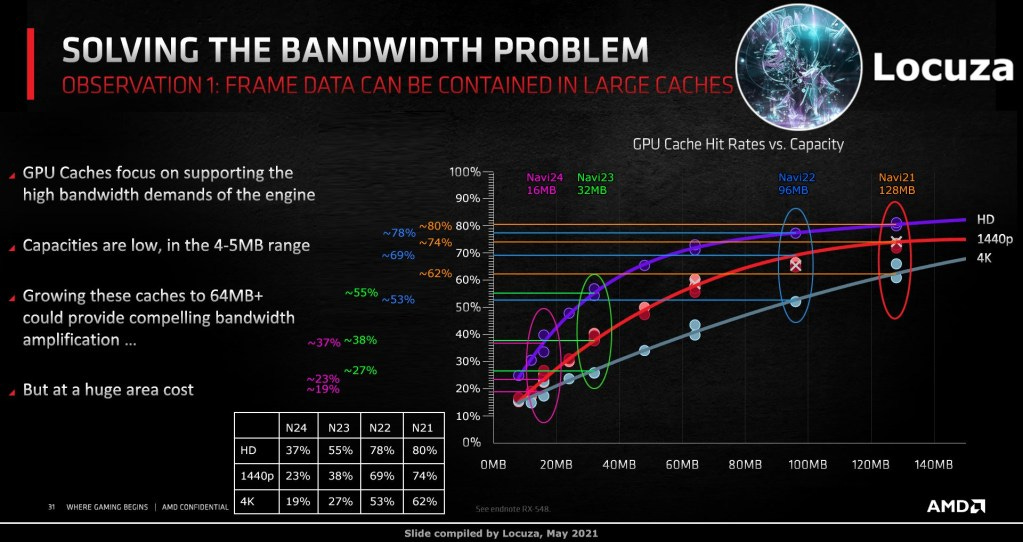
This is interestingly the same amount of L2 cache as AMD’s Navi 22 GPU has “Infinity Cache”. As an aside, we hope Nvidia names their large L2 “Nfinity Cache” just to troll everyone. AMD’s Infinity Cache is an L3 cache, but despite the cache hierarchy differences between the two vendors, we expect the general trend of hit rates to be the same. In AMD’s case, the hit rates are 78% in 1080p, 69% in 1440p, and 53% in 4k. These high hit rates assist with reducing memory bandwidth requirements. If Nvidia’s large L2 works in a similar manner, it will greatly assist in feeding AD102 despite the small increase in memory bandwidth. The top end configuration of Ada should come with 24GB of GDDR6X, but we expect there to be configurations that are cut down from this.
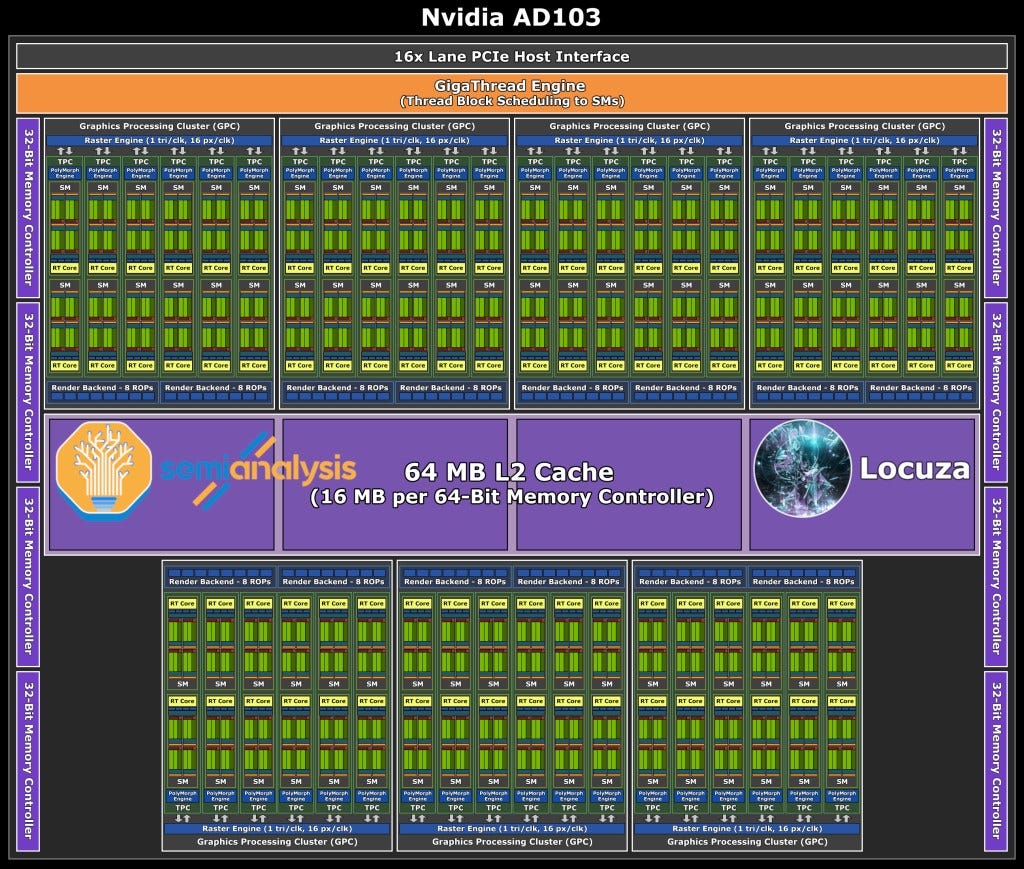
AD103 is quite interesting as a configuration estimated at ~379.69mm2. Versus AD102, it is a huge downgrade. This may be the largest gap in recent memory between the top die and the 2nd die in a GPU generation with AD102 having more than 70% more CUDA cores vs AD103.
The other interesting thing is that the CUDA core counts are the exact same as the current generation top end GA102. The memory bus comes in at 256-bit bus, much smaller than AD102’s 384-bit bus. As such gaming GPUs based on AD103 will max out at 16GB but cut down variants will likely exist. Despite memory bandwidth being much lower than GA102, the inclusion of a 64MB L2 cache will still allow this GPU to be fed.
Given Nvidia will be utilizing a custom TSMC “4N” node, we expect they will be able to clock higher than GA102. The clock increases combined with architectural advancements will allow AD103 to perform better than the current generation flagship, RTX 3090 Ti; if they bring it to desktop with high power consumption. It’s important to note that GA103 never came to desktop and is only available on the top end of laptop GPU, so this could happen again with the Ada generation.
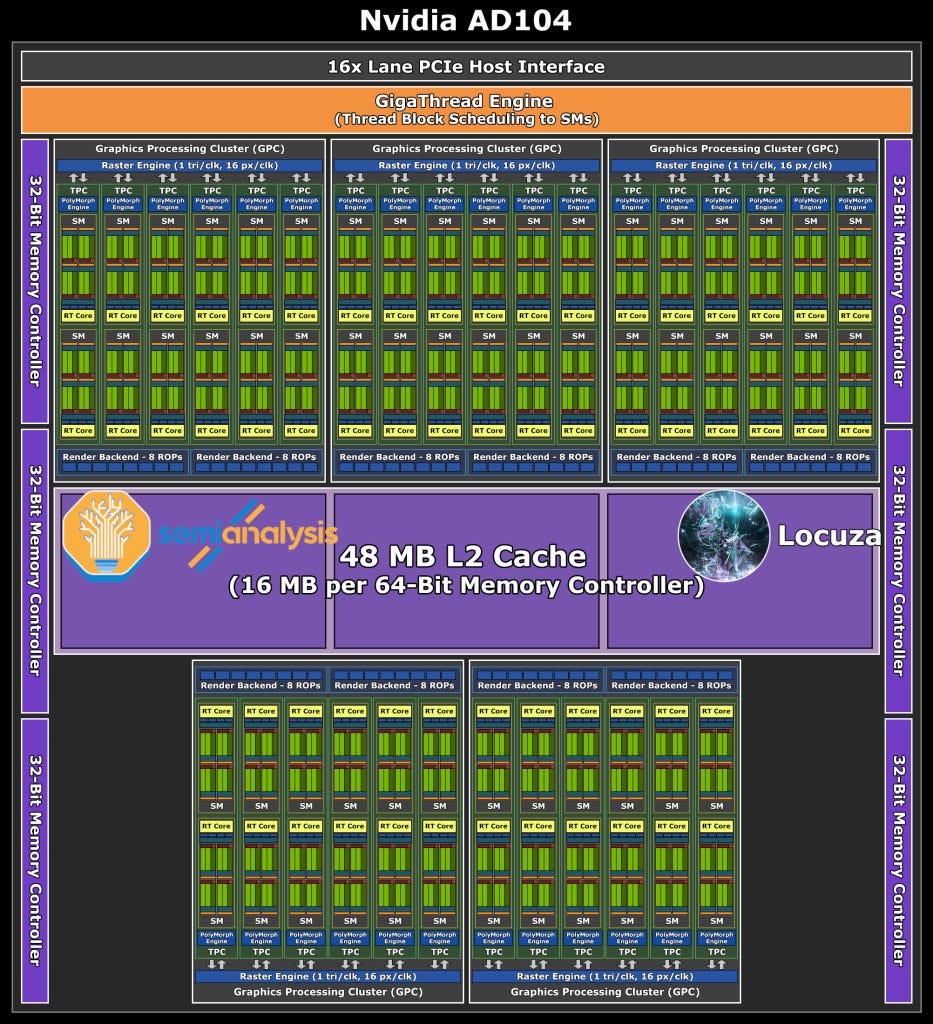
AD104 estimated at ~300.45mm2, is the sweet spot in the Ada line-up due to its performance and cost effectiveness. The 192-bit bus leads to 12GB memory for gaming GPUs which is high enough capacity, while keeping the bill of materials (BOM) down to a reasonable level. Simultaneously, Nvidia GPUs tend to have the 104 designs have similar performance to the prior generation 102. If this trend keeps up, the cost/performance should be excellent. In fact, it may even have more as Nvidia likely pumps clocks a decent amount to hit above 3090 performance levels. We expect Nvidia to go as high as 350W or even 400W for the top AD104 desktop GPU with GDDR6X. As such, we expect this will be the GPU most enthusiasts end up purchasing. The GPU can also be highly efficient, which we expect without G6X memory and with clocks pulled back a bit. It should perform admirably in the ~90W to ~135W laptop arena as well.

AD106 is the true mass market GPU estimated at ~203.21mm2. It will likely be the highest volume GPU in the lineup as 106 GPUs were the highest volume for the Pascal, Turing, and Ampere generations. Due to the 128-bit bus, it will mostly come with 8GB memory. In the top end configuration, we expect it to perform similarly to GA104, which maxes out in the 3070 Ti. That assumption may be a bit overly optimistic given there are only 3 GPCs in AD106 versus 6 GPC in GA104. This GPU will also be the highest volume GPU in mobile. With 32MB of L2 cache, the GPU cache hit rates are likely 55% in 1080p, 38% in 1440p, and 27% in 4k like AMD’s Navi 23.
Before we move onto the baby of the generation, AD107, we need to give a bit of background. The data posted on twitter from the leaked files does not specify the cache size for this GPU. The prior GPUs assumed the same 16MB per 64-bit memory controller / frame buffer partition (FBP). With AD107 this wouldn’t make much sense because the GPC count and bus width remained identical and TPC per GPU only fell to 4. If the L2 cache stayed the same, then die size would only fall from ~203.21mm2 to ~184.28mm2. This tiny decrease would not be enough to separate the two GPUs in the stack.

Instead, we assumed there would be a similar relationship as TU116 and TU106 from the Turing generation of GPUs. The TU116 had an FBP with 0.5MB of L2 cache instead of 1MB like the TU10x dies. If we apply the same pattern of 50% L2 cache per FBP, AD107 ends up being estimated at ~145.54mm2. This seems much more reasonable for product positioning and cost.

With these assumptions, AD107 seems to be a great mobile GPU. It is adjusted down to 8 lanes of PCIe as more are unneeded and Nvidia generally shifts their bottom GPU down to this lane count. It would have enough performance to blow away even Intel’s best Meteor Lake iGPU configuration, but it would be cheap enough to end up in some lower cost laptops.
Overall, Ada is a quite interesting lineup. At the top end, there is quite the increase in performance (and power consumption). AD102 is of similar die size as GA102, but on the more expensive customized TSMC 4N process technology rather than the cheaper customized Samsung 8N process technology.
The density increase from a TSMC N4 derivative is quite large relative to a Samsung’s 8nm derivative, which justifies the cost. Interestingly despite being a much newer node, SemiAnalysis sources report that TSMC N4 actually has a slightly better parametric yield than Samsung’s 8nm node despite similar catastrophic yields. This is mostly a non-issue for GPUs as nearly every die can be yield harvested.
The rest of the Ada lineup comes away a lot tamer in terms of die sizes and overall BOM. Performance should generally be above Ampere at the same power with a decently lower cost to fabricate despite much higher wafer costs. We played around with wafer costs and die calculators quite a bit to come up with some estimations on cost, but ultimately Nvidia’s cost is only a portion of the end user price. Nvidia sells the die with their markup and negotiates memory pricing for the ODM/AIB to use. The ODM/AIB partner still has to buy and integrate that memory as well as power components and cooling at presumably a low margin.
Nvidia seems to have balanced their L2 cache sizes with memory bus widths optimally. Memory sizes will stay reasonable as most GPUs will have 16Gb G6X or G6. In general, AD104 is replacing GA102 and AD106 is replacing GA104 in performance tier. The memory cost is identical and cost to fab the die is less. The board level components such as packaging, cooling, and power components are cheaper due to generally better efficiency and smaller boards. When we compare the same die in the stack such as GA104 vs AD104, there is an increase in memory sizes, but this was needed as 8GB is too little for the segment while 16GB is too expensive.
The fears of high power should be taken into consideration though. Nvidia is likely pumping power for each die similar to what the prior generation did. In fact, we can imagine they will push power to what 1 die higher up in the stack did, IE the top AD104 configuration reaching 3080 levels of power consumption and top AD106 configuration reaching 3070 levels of power consumption. Rumors point to the top AD102, breaking new records for GPU power consumption.
Next, we will break down how we arrived at these die size estimates. The first step in the die size analysis was to gather the architectural changes regarding Ada and comparing them to Ampere. The SM architecture is 8.9 instead of 8.6, so this is mostly a generational improvement. As a result, we assumed a 10% increase in SM size. We aren’t sure what the SM architecture changes are, but they could potentially include a 192Kb L1 caches and tensor cores. The highest probability change in our minds is the addition of a new 3rd generation RT core. On the IO front, the leak indicates that NVLink has been entirely removed from the lineup which indicates that Nvidia is not going to push the Ada lineup for multi-GPU datacenter and professional visualization applications. We expect PCIe 4.0/5.0, a better memory controller for higher speed GDDR6X, and DisplayPort 2.0 will be included. An updated NVENC and NVDEC are likely included which should bring AV1 encoding to the mix.

The biggest change with Ada is of course with the L2 cache. Instead of a small L2 cache, Nvidia seems to have taken a page from AMD’s Infinity Cache book and used much larger caches across the board. Given we have most of the specifications, Ampere’s GA102 IP blocks can be used to create a hypothetical GPU die with similar specifications to those of AD102. This would not contemplate some of the changes such as SM architecture change, larger encoder block, a change to PCIe 5.0, Displayport 2.0, or a tweaked memory controller for GDDR6X.
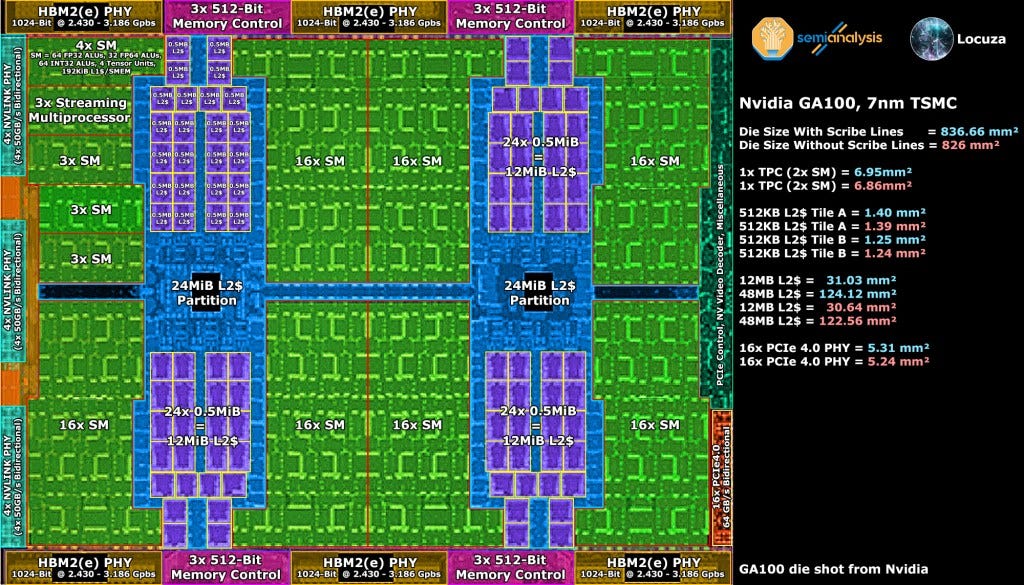
By using the GA102 building blocks, we arrive at a die size of 1629.60mm2 for this hypothetical Ampere GPU with the same configuration as AD102, but on 8nm. The immediately obvious thing you will notice is that the L2 cache is titanic. AMD has a larger capacity L3 Infinity Cache on their Navi 21 GPU, but they do not allocate as large area of an area dedicated to this cache. Yes, AMD is on a denser N7 node, but that is a tiny part of the puzzle. Most of the difference in density comes from the layout and configuration of that L2 cache.
GA102 uses 48, 128KB slices of SRAM with 1MB of L2 per 64-bit memory controller / frame buffer partition (FBP). GA100 on the other hand uses 80 512KB slices of SRAM. These larger slices appear to vastly improve the density, as seen in the comparison to AMD’s L2 cache. The density increase of GA100 is far more than just that of the process node shrink. The same effect can be seen with AMD’s L3 Infinity Cache.

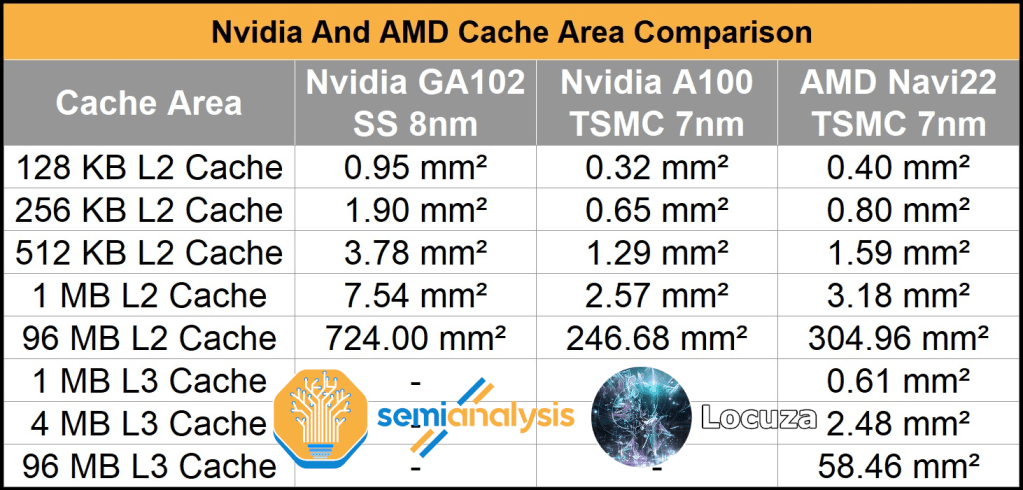
While AMD is not as good as Nvidia in many elements of design, we believe they are undoubtably better in some areas such as cache and packaging. We believe much of this stems from their CPU team’s pedigree. AMD is very good at making extremely dense high-performance caches for GPUs as shown by their Infinity Cache. In fact, in our final die size estimates, Nvidia’s 96MB of L2 is still nowhere near as dense as AMD’s 96MB of L3 Infinity Cache.
Regardless, a shrink from Samsung 8 to TSMC 4 alone would not make the GA102 building blocks reach a reasonable die size. Instead, there was an architectural rework required in the cache design. The leaks tell us there is now 16MB of L2 per 64-bit memory controller at the FBP for AD102. We estimate Nvidia will move to 48, 2048KB slices of SRAM.
With this cache configuration, we can calculate the theoretical cache bandwidth with these figures. AMD has 1.99TB/s Infinity Cache bandwidth on Navi 21 at 1.94GHz. If we assume Nvidia is running at the same 1.94GHz on AD102, then they will be able to achieve 5.96TB/s of bandwidth at their L2. Clocks will differ in the end products, but we expect somewhere around 2.25GHz will be realistic for Ada in desktop. We expect RDNA3 to clock above 2.5GHz on desktop. Nvidia is making a design choice of using a high bandwidth cache at the cost of some density. Nvidia could have introduced a higher density cache with 8-16MB per slice. This would likely give their L2 similar density to that of AMD’s Infinity Cache, but it would cause L2 bandwidth to drop below that of Ampere's. In the end, that is likely not an option.
We came up with estimates for what this different cache architecture would do to the area of the AD102 building blocks L2. Then we applied shrink factors to TSMC’s N7 and another to TSMC N4. The SRAM appears to use a 60:40 split of SRAM to logic, which helped influence the SRAM shrink we used. We applied a 10% gross up factor to the SMs to account for any architectural changes there and had different shrink factors to the various pieces of digital logic based on their mix of SRAM to logic which was generally 30:70.
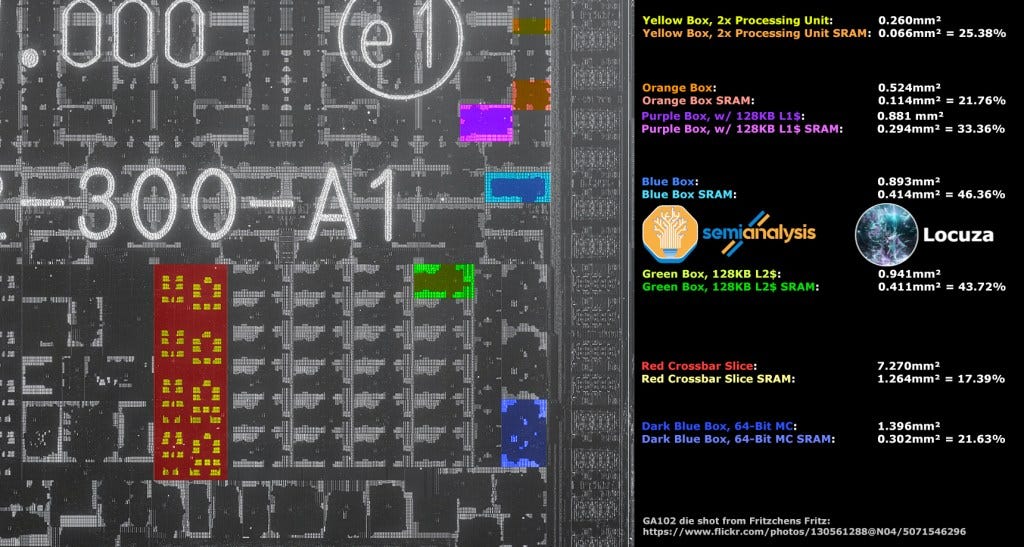
Lastly, we kept the analog portions of the die identical as the shrinks would be small, but these would be equalized by potential upgrades that would increase area such as PCIe 5.0, GDDR6X memory speeds, and DisplayPort 2.0. The NVLink was removed in these figures. In the end we arrived at the ~611.3mm2. This independently lines up with what kopite7kimi has stated about die size being around 600mm2.
After gathering a small overview, we could start with configurations for the rest of the lineup. GPC, counts, TPC counts, L2 size, command buffers, various PHYs, crossbars, etc can all be dynamically scaled down depending on the GPU configuration. All the numbers we chose for shrink factors are somewhat arbitrary based on our fudging of statements from TSMC and real products, so in the end it is a bit of a shot in the dark. For AD107 we backed off slightly on the different cache architecture as we had a smaller amount of cache per FBP.
Overall, Ada Lovelace doesn’t seem to be a massive departure architecturally from the current Ampere architecture, but the changes it does bring such as improved ray tracing cores, improved encoders, and the larger L2 cache will bring performance up considerably while keeping costs down despite being on a more expensive custom TSMC N4 based node. Nvidia is keeping with the tradition of keeping memory sizes are well balanced across the stack with a modest increase in memory size per level. L2
Versus AMD, rumors point to very high performance but also high cost for the top end. We are much more interested in their Navi33 chip which should fall in somewhere in between AD104 and AD106. The range is large, but leaks point to it being a good competitor in the mass market. AMD is currently massively behind in ray tracing performance and the lack of many differentiated software features such as DLSS and Broadcast do hurt their competitiveness, but we believe this will be the most competitive GPU generation in a decade.
GPU prices are falling fast as Ethereum 2.0 slams on the breaks of mining demand and consumers shift their spending mix away from goods and towards services. These factors in combination with higher inflation mean that we predict Ada Lovelace (and RDNA 3) GPU prices will be quite good price to performance in the $400 to $1,000 market. The top end of the stack will most likely amazing levels of performance but cost more. In short, the consumer will win!
Since you're here, if you enjoyed the article, check out some other analysis of chips, such as our deep dive on Tenstorrent and their hardware/software roadmap. Tenstorrent is the company that the famous Jim Keller is currently the CEO of!
Locuza's role in the analysis of GPU die area was crucial. I highly recommend our subscribers from competitive analysis teams at semiconductor firms reach out to him and work with him!
Nice work, Dylan
You miss the elephant in the room afaict.
The top die (their key AI warrior) is double the size of their historical comfort zone (for which there are sound reasons laws of physics/power/heat/yields/economics...).
Why this desperation?
The answer is AMDs AMD's MCM GPUs on Fabric.
This is huge.
It is what zen chiplets did for CPU.
Even NVs software moat cannot withstand the raw muscle AMD can cost effectively apply to BIG tasks.
AMDs modules allow 2x epyc & 4x GPU to interconnect at 3TB/s via Infinity Cache. Lacking their own platform after the ARM fail, they know very well they face a big threat in increasingly Epyc dominated data centers.