


How Nvidia’s Empire Could Be Eroded - Intel Network And Edge Has The Playbook
How Nvidia’s Empire Could Be Eroded - Intel Network And Edge Has The Playbook

Nvidia’s software expertise has propelled them to completely dominating the markets they operate in. This dominance is the most apparent in AI training workloads, but it also extends to the arena of discrete GPUs for PC gaming. Nvidia created an architecture that is highly flexible and programable with the software middle wear on top which offers developers the ability to tap into unheard of levels of performance with nearly the same ease of use as CPUs.
This same software then locks users into Nvidia hardware and prevents other firms from getting developer attention for their potentially better hardware solution. Nvidia is now leveraging this same playbook to extend their business to automotive, AI enterprise software, and omniverse enterprise software.
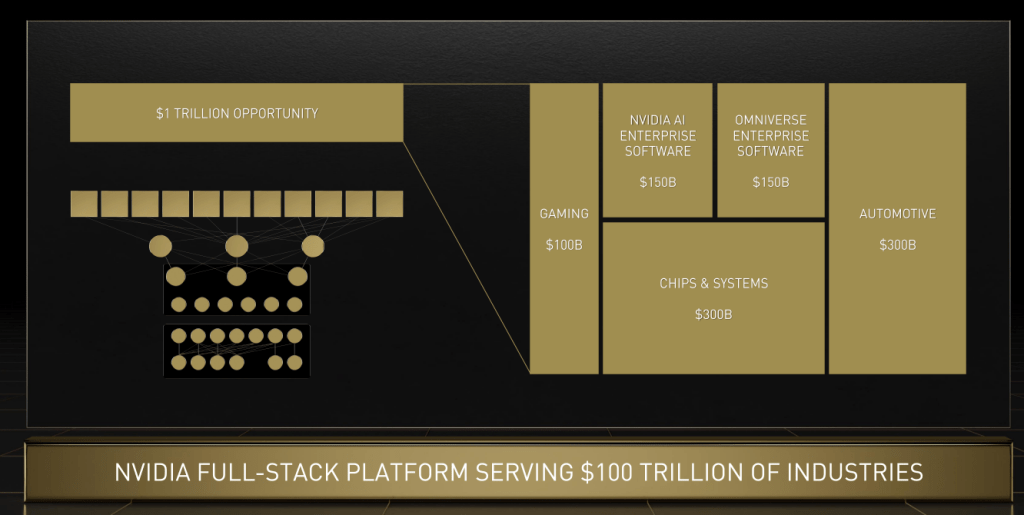
Nvidia looks unstoppable, but there is competition with a successful strategy for preventing Nvidia from swallowing the entire industry.
Believe it or not, Intel has the playbook. We had the opportunity to interview Dr. Sachin Katti, Chief Technology Officer of Intel’s Network and Edge Group to discuss this playbook. We also spoke with Matthew Formica, Senior Director of AI Inference at Intel. Both these leaders within Intel’s Network and Edge Group are highly focused on hardware and software codesign and optimization.
Rather than trying to substitute one closed source Nvidia platform for replacement Intel ones, they have a history of creating open platforms that the industry has adopted. First, we will go over some of these open standards and platforms that Intel has created before moving on to what Intel is doing to fight Nvidia in their stronghold markets.
Arguably the most successful example deals with telecommunications networks, specifically 5G networks. Intel went from effectively a non-player to now capturing upwards of 50% market share in base stations. This has come directly from the software platform that Intel has built to leverage applying their commodity hardware to this market.
The telecommunication network is split into 2 functions, the radio access network, which handles sending and receiving data from the end user, and the core network which handles the packet processing and traffic related to the network. Intel has long since invaded that core network by offering commodity x86 hardware. The big advantage was that telecommunications providers switched to a cloud like model with containerization and virtualization.
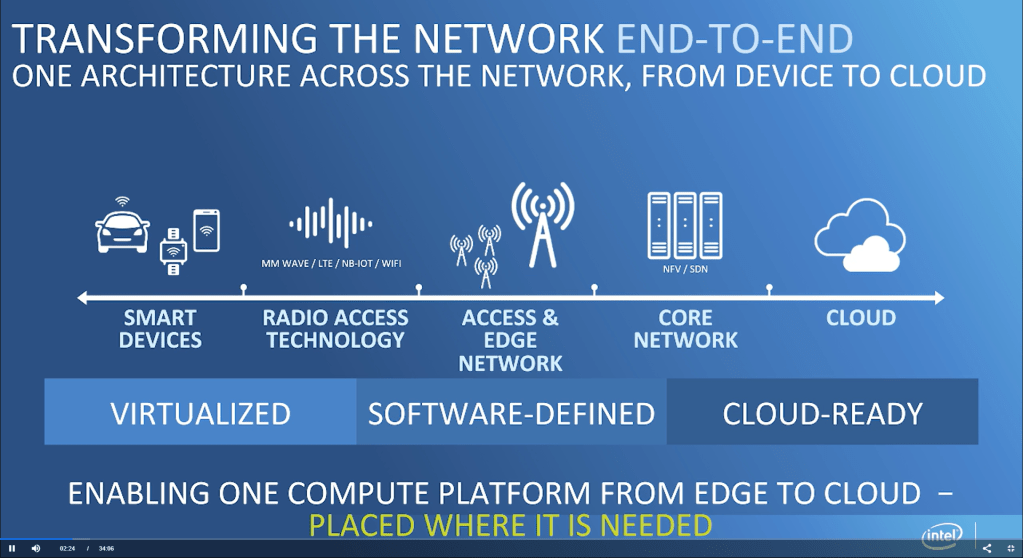
With the radio access network, this is a more recent change. In the days of 3G and 4G networks, the radio access network base stations were often built upon custom ASICs from the likes of a Ericsson, Nokia, or Huawei. These custom ASICs were in charge of running signal processing and packet processing for network functions and involved very low-level network software. In essence, the whole stack was highly customized. Highly customized is great when performance and energy efficiency are there, but it also causes higher unit costs due to higher fixed costs. Highly customized silicon solutions also tax software engineering resources.
There is a trade-off between performance, energy efficiency, and programmability.
Dr. Sachin Katti, Intel Network and Edge Group Chief Technology Officer
That’s where the OpenRAN Alliance comes in. The entire purpose of this open organization is to attempt to open up the 5G infrastructure market for radio access networks. Dr. Katti was deeply involved in the founding of the OpenRAN Alliance and currently co-chair’s it.
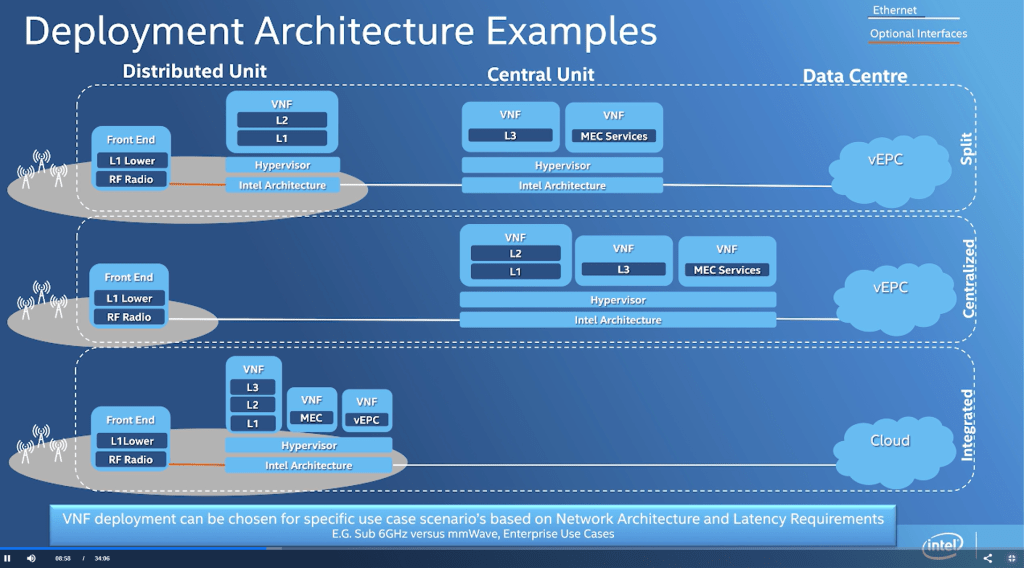
Intel has purpose built a software stack called FlexRAN to move some of these workloads onto commodity hardware to maximize programmability but keep performance and power efficiency high. While this software itself is completely open and adheres to the core principals of ORAN and VRAN, it does require the user run it on Intel hardware. This reference architecture has been adopted by Verizon, Dish, Rakuten, and many others. Instead of buying base stations which are integrated pieces of hardware and software from an Ericsson, Huawei, or Nokia, telecom operators can procure servers from a commodity server player such as Dell or Supermicro.
These telecom operators can then run a cloud stack on it which could come from RedHat, VMWare, or similar providers. AWS, Azure, and Google Cloud are also developing software stacks for this purpose. In the end, base station software is run as a containerized application on top of commodity hardware. This alternative means that deploying a 5G network becomes similar to deploying to any other application that would run on a Xeon based server.
The issue with moving the radio access network to commodity hardware is that the workload is a digital signal processing workload. This DSP workload includes code that is difficult for CPUs to process, such as forward error correction (FEC). Latency requirements are on the order of 1 millisecond for layer 1 of a radio access network. Given the speeds of 5G networks, running this code on commodity CPUs could cripple performance and cause power and costs to soar.
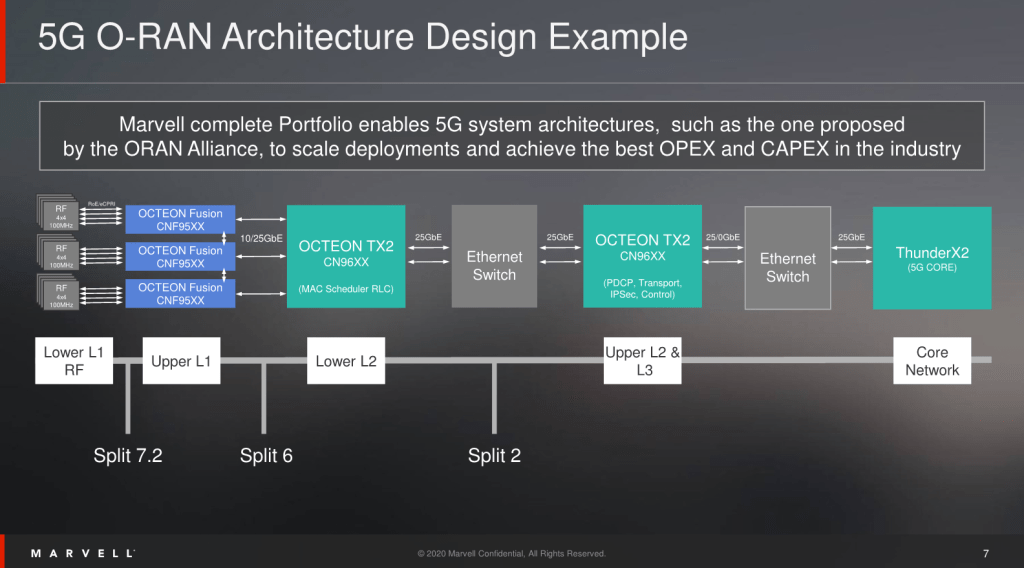
The various processing of a radio access network is split into many layers. The digital signal processing of radio signal to packets is generally grouped into what the industry calls Layer 1. Customized hardware is still currently required for the Layer 1 code. Intel has their Mount Bryce eASIC, Marvell has their Octeon platform, and Qualcomm has their DU X100. Nvidia is attempting to use GPUs for this Layer 1 acceleration, which we discussed in our article about Qualcomm’s 5G infrastructure silicon last year. We have yet to see Nvidia’s solution gain any major traction, so we are unsure if it is viable. All these solutions involve utilizing a specific hardware accelerator for Layer 1 which sort of defeats the purpose of OpenRAN. The Layer 1 processing is a black box that cannot be modified or substituted easily.
Intel is changing this model entirely. They have announced they will be integrating FEC and other 5G network related instructions directly onto a variant of Sapphire Rapids. This would be a different piece of silicon from the Sapphire Rapids which Intel will launch for datacenters this quarter. It is called Sapphire Rapids EE. We suspect this will use the same coprocessor framework that Intel’s AMX utilizes. The engineering resources for this solution are not too high given much of the work is replicated from the existing datacenter silicon.
All the flexibility of a CPU is maintained and Intel’s FlexRAN software allows for the easy mapping of software to accelerators. Sapphire Rapids EE provides flexibility to customers in how they map the acceleration hardware to the right part of the vRAN workload and thus best meets the needs of the operators versus the prior solution that forces the entire Layer 1 into an inflexible hardware accelerator. Programmers can write in standard C or C++ and have the compiler figure out how to map different parts of the code to acceleration hardware. Intel’s excellent compiler work here is critical for this to succeed.
In addition to benefits in flexibility and programmability, there are power and performance improvements as well. A single memory pool can be shared, and there are no power and latency penalties for going across a PCIe bus. Shifting data back and forth across the PCIe bus would be very costly.
Intel’s involvement in the creation of the OpenRAN standard is in stark contrast to what Nvidia tends to go for which is a closed solution built on their hardware and software. Intel embraced an open method so that other hardware providers such as Marvell and Qualcomm can get involved. At the same time, Intel has utilized their incredibly flexible CPU hardware with the right amount of integrated purpose-built hardware to achieve amazing programmability, performance, and power. Their software teams have built a stellar compilation and task scheduling framework inside the open source FlexRAN software solution. The co-development of more specialized hardware with open and easy to use software frameworks has allowed Intel to go from a non-player to majority market share holder.
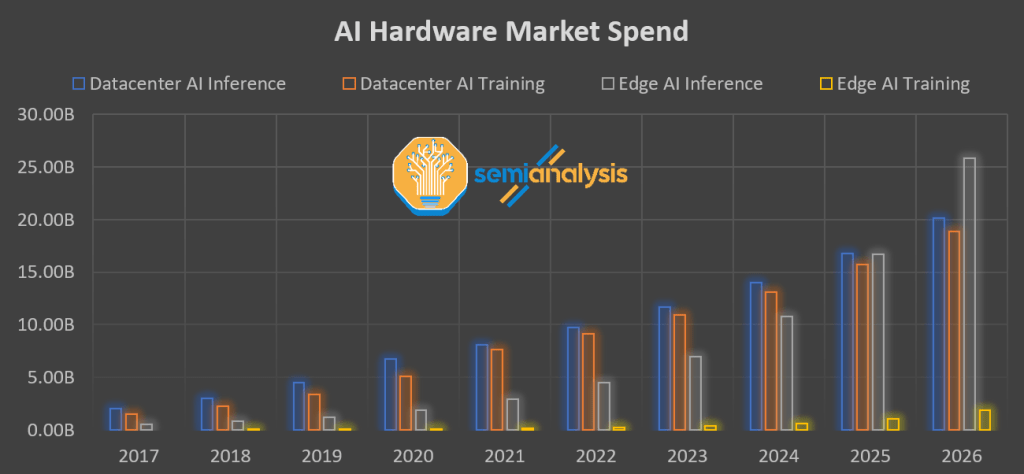
Intel’s Network and Edge group has used this playbook for the AI inference market aswell. OpenVINO is an open-source tool kit for vision inference, neural network optimizion, and inference deployment for AI models. It is a layer above Intel’s OneAPI foundational level software. Other software and hardware vendors can contribute to OpenVINO and use it freely. The purpose of OpenVINO is that it can take the back half of PyTorch or TensorRT and act as a compression library for that model. It tweaks and customizes the model specifically for the intended target hardware. The runtime library then takes the model and distributes the inference workload to the available compute in the most efficient way possible.
OpenVINO supports a wide array of Intel hardware. Intel CPUs alone can vary in terms of their AVX support levels. Sapphire Rapids CPUs bring an AI coprocessor into the fray. Furthermore, Intel has a variety of GPU architectures deployed in integrated and discrete form factors. Lastly there are also Movidius based VPUs and FPGAs. A variety of hardware can be utilized. OpenVINO enables the AI models to be mapped directly to whatever hardware you have for the most efficient inference possible. It knows the correct DNN math libraries to utilize for the best possible result. This is all abstracted away from the developer.
The developer just says go run inferencing on whatever compute you find. That's one of the big things we announced. OpenVINO knows the characteristics of all the underlying hardware, and so instead seeing everything as nails to hammer in, you can essentially pick the right mix in a given edge deployment of accelerators and compute that hit your power and performance characteristics that you need, and so that makes it more tailored from an ROI perspective to a given edge deployment.
Matthew Formica, Senior Director of AI Inference at Intel
The edge is quite a unique area where heat and power play a big role. For example, there are factories where the devices must be fanless because of fire regulations. This would drive targeting the AI workload onto one set of accelerators instead of another perhaps more performant set of accelerators. OpenVINO attempts to make this seamless.
That principle of the edge driving unique architectural considerations that don't lend themselves to macro benchmarks plays out exactly the same way in AI.
Matthew Formica, Senior Director of AI Inference at Intel
Habana was also noticeably missing from the OpenVINO support list. This makes sense given it has been quite unsuccessful in the market. SemiAnalysis believes Habana still has not even reached the level sales of Intel’s former Nervana AI chips, despite Intel having dumped multiple billions of dollars into Habana. We asked Matthew about support for Habana AI inference accelerators within OpenVINO and this is what he had to say.
As accelerators mature at Intel, we have the conversations with them about “Is it time to write a plugin for OpenVINO?”
It’s going to be accelerator by accelerator when it’s time for them to hit that scale point in their curve to have the general developer community be ready to access that hardware. Habana is less mature than the CPU and we constantly work with them and other accelerator teams at Intel to add support.
Matthew Formica, Senior Director of AI Inference at Intel
This response made complete sense to us given Habana’s 1st generation hardware had lousy performance and efficiency. According to our sources, the 2nd generation hardware is running later than what they had originally promised when Intel was pitched to purchase the company. Software support has been a big sore spot with Habana, and Habana still does not support OneAPI. An AI developer and researcher who is a friend of SemiAnalysis tested out the preview instances of Habana on AWS told us Habana is not competitive even with Nvidia’s last generation Volta and Turing, let alone the current generation Ampere or next generation Hopper. Habana will not be competitive in any shape or form until they fix the software and have competitive hardware. We believe this is not likely to occur over the next 3 years.
OpenVINO has had great success on the edge, but it is also making inroads in the cloud and PC. The launch of Sapphire Rapids will likely come with some major announcements of wins for OpenVINO given the integrated AMX AI accelerator is being heavily lauded for inference workloads by certain cloud vendors. On the PC, Adobe’s Photoshop is utilizing OpenVINO for some plugins and there is a Game Dev Kit which enables style transfer, object detection, and world creation to be accelerated by Intel’s AI hardware.
While OpenVINO is open, mostly only Intel hardware is supported. There is an Arm plug in as well. As OpenVINO continues to gain traction, other hardware developers likely will be forced to support it. Intel will have the first movers’ advantage as their created the ecosystem and have much deeper support. Intel has already sold multiple billions of dollars of chips today that run OpenVINO on the edge to customers such as FedEX who selected Intel for AI inference over Nvidia based solutions.
Another example of the hardware-software codesign playbook comes with the networking angle with infrastructure processing units (IPUs) and networking switches. CPUs currently run many workloads beyond the business logic such as container runtime, Kubernetes, virtual networking, storage offload, remote storage, storage virtualizations, service mesh, and security related applications. The purpose of IPUs is to separate the infrastructure code from that of the tenants that are renting servers or utilizing services running on them. This airgap between infrastructure and tenant is critical for security and TCO.
Intel has created a software stack called IPDK which is available at IPDK.io. This competes directly with Nvidia’s DOCA for DPUs. Marvell and Pensando, which was recently purchased by AMD for $1.9B, also have their own software stacks. IPDK is unique in that it is a public development kit that abstracts out the IPU hardware. It can be run on any hardware, not just Intel’s IPUs due to the consistent abstraction, including Xeon servers and even competitors DPUs. Marvell for example has presented their Octeon DPUs running on IPDK.
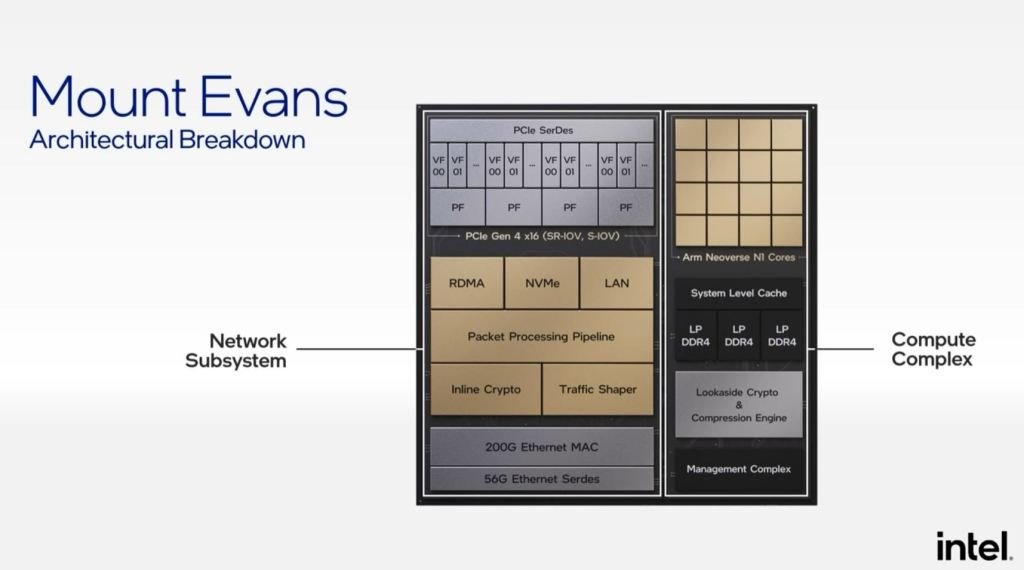
This open software stack is gaining traction, and it prevents Nvidia from monopolizing the emerging field of DPUs which could be >$50B TAM in a handful of years. This strategy also appears successful given Intel has wins with the Mount Evans IPU at firms like Google and Alibaba. Firms such as Amazon, AMD, and Nvidia could adopt this software platform for their own hardware.
IPDK supports all the capabilities needed for a DPU such as RDMA, remote storage, and pass layer components like Kubernetes. IPDK targets what multiple different forms of software that already exist do. Part of the functionality is similar to Microsoft Sonic which is a network operating system that abstracts out NIC cards and switching. IPDK also abstracts out the compression and encryption capabilities of the hardware. It also abstracts out lower-level storage acceleration.
IPDK, think of it like a bunch of OS libraries that would be layered in Linux. It will still look like Linux, but it will have all these special things that will abstract out all of this hardware and make it available as operating system resources. Then you can write the equivalent of a virtual network capability, or a V-Switch, or you can write an RDMA implementation on top, or you can write even service mesh. Service mesh is an HTTP stack with lower-level TCP and some load balancing.
What we are doing essentially here is taking advantage of these OS capabilities, these hardware capabilities to run HTTP more efficiently, to run TCP more efficiently and offload it from the main CPU. Think of IPDK as a set of abstractions that sit on top of this heterogenous hardware and expose it in a consistent manner to all of these application on top.
Dr. Sachin Katti, Intel Network and Edge Group Chief Technology Officer
IPDKs will enable new architectures by allowing a transition to diskless architectures on the edge and in the datacenter. In many cases you don’t want storage in the edge device or server for cost, power, or space reasons. IPDK and Intel’s IPUs enable diskless architectures by offering hardware acceleration to keep performance degradations and power impact to a minimum.
Dr. Sachin Katti, CTO’s of Intel Network and Edge Group, is a professor at Stanford. Dr. Nick McKeown, General Manager of Intel Network and Edge Group, is also a professor of Intel Network and Edge Group. They developed P4 as a research project out of Standard. The purpose was for creating software defined networking and decoupling the data plane from the control plane. P4 stands for programming protocol independent packet processors. This open language is now supported by Intel, Nvidia, Cisco, Marvell, Google, Microsoft, and many others.
What people realized very quickly is that you also need data plane programmability. You need to be able to specify to a switch or a NIC card how it should manipulate the packet, how it should manipulate the headers of a packet. In the past, that was done with very proprietary means that either a Cisco or a Broadcom would expose, but it was really not portable. So P4’s vision was that you can write with the domain specific language, how you want every packet to be processed in the network, and compile it down to run on our Tofino switches, compile it down to our IPU's, compile it down even to virtual implementations in Xeon.
Dr. Sachin Katti, Intel Network and Edge Group Chief Technology Officer
Intel’s IPDK supports P4. Nvidia’s DOCA still does not support P4. Sources say Nvidia's DOCA will support P4 later this year. Nvidia is lacking behind Intel and Marvell in software support for their DPUs. This time to market advantage with software capabilities and deployment is how Intel can fight back Nvidia’s titanic software-hardware optimization lead in the server space.
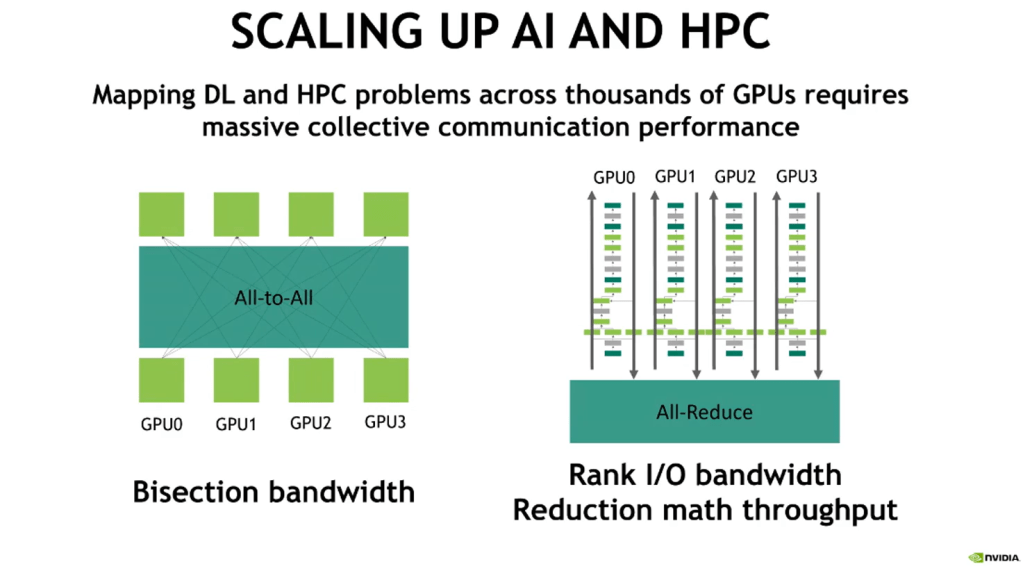
Nvidia supports P4 in some of their NICs and Switch silicon, but they also have created SHARP, Scalable Hierarchical Aggregation and Reduction Protocol into their switches. Some capabilities of P4 are replicated in SHARP, but others are not. Nvidia’s SHARP includes accelerated collectives include write broadcast (all_gather), reduce_scatter, and broadcast atomics. Intel is battling Nvidia’s proprietary SHARP with P4. Intel’s 25.6T Tofino 3 networking switches have similar large AI model training capabilities.
When training really large models, you have these functions that need to collect gradients from a number of different places and combine those gradients and pass the gradient onto the next layer. This is a typical training workflow, now typically what you do is ship it to a server, all of those different variants, the server would do that processing, and then send it back, but it's wasteful because all of those are probably going through the same switch. In P4, what you can do is you can actually write that gradient processing step as a piece of P4 code that collects the appropriate packets from the different servers, does that that crossing step inside the switch itself, and then just sends the update onto the next server. You short circuit that tromboning where you need to go to another server and come back.
Dr. Sachin Katti, Intel Network and Edge Group Chief Technology Officer
Intel’s fastest growing business within Network and Edge is the Internet of Things Group. There is a wide variety of low-level software. Intel also builds a lot of application layer software as well. One of these is Edge Insights for Industrial which also supports OpenVINO. The entire purpose of this software is for making it easy for Intel’s industrial customers to build industrial automation applications. This is an incredibly fast growing vertical, and this software and hardware optimization makes it easy for clients to deploy emerging workloads on the edge while also tying them into Intel hardware platforms.
Intel has used this same strategy with Open Visual Cloud which is built for content delivery networks. They have also built SmartEdge which helps enable the Kubernetes cloud stack on edge processors.
To summarize, the playbook for stopping Nvidia from dominating with their hardware-software co-optimization across all of datacenter, networking, and edge compute, is succinctly described by this quote from the conversation.
Our job is to show the world that you can consolidate and run all of these different specific point specific workloads on general purpose platforms and consolidate them using containerized or virtualized technologies. Often the world is too conservative to adopt this and so we have to show them how to do it. Once they are adopted, then it gets going, the flywheel gets going, people invent more and more things.
We like to create languages that abstract the hardware out, allow you to write the specific logic that you need for that domain, whether it's packet processing in the case of P4, whether it's IPDK for infrastructure processing, whether it's FlexRAN for radio processing, and compile it down to the hardware at runtime depending on what you need.
NEX builds not only hardware, but it also builds software to show the world it is feasible. We invest in software to reduce the time to market to build these kinds of applications.
Dr. Sachin Katti, Intel Network and Edge Group Chief Technology Officer
Intel Network and Edge Group has the playbook, and now it’s up to Intel’s CEO Pat Gelsinger and CTO Greg Lavender to implement it across the company. Pat Gelsinger and Greg Lavender come from VMWare, so if anyone can build it, it is them.
And increasingly, that's built on a common end-to-end software platform that Greg described our oneAPI approach. But our software assets are one of the underappreciated competitive advantages that we've had. We have these 4 decades of hardening of the software technologies. And having run a software company, and sometimes I wonder why did God take me on an 8-year journey to come back to silicon but it was learning how to become a software executive at scale.
And software is like a fine wine. It just takes time to harden those components. And we're creating these core platform capabilities and then driving them into the open-source community efforts. We're the leading provider of Linux and Linux OS technology.
In fact, with the 19,000 software engineers we have, I have more software engineers working for me today than when I was running a software company. It really is quite spectacular. But software is not just 1 thing. Developers are everywhere. And for us, software is key to exposing our silicon features, optimizing the software to run best on Intel, but pulling that platform value up the stack. And our software strategy, if you describe it in just 2 words is move up. And what Greg described is how we're moving up the software stack.
Today, about $100 million or so from software licensing subscription. In the future, Greg's agenda, a lot more. And the value of software of exposing our platform of creating and enabling an industry of developers is so critical to the future and why I was so excited to have a leader like Greg join us here on this journey, making software a competitive differentiator for Intel on this journey.
Pat Gelsinger, Intel CEO
Clients and employees of SemiAnalysis may hold positions in companies referenced in this article.
...and when is Sapphire rapids going to be shipped to customers?