


Google AI Infrastructure Supremacy: Systems Matter More Than Microarchitecture
Google AI Infrastructure Supremacy: Systems Matter More Than Microarchitecture
From DLRM to LLM, internal workloads win, but how does Google fare in external workloads?



The dawn of the AI era is here, and it is crucial to understand that the cost structure of AI-driven software deviates considerably from traditional software. Chip microarchitecture and system architecture play a vital role in the development and scalability of these innovative new forms of software. The hardware infrastructure on which AI software runs has a notably larger impact on Capex and Opex, and subsequently the gross margins, in contrast to earlier generations of software, where developer costs were relatively larger. Consequently, it is even more crucial to devote considerable attention to optimizing your AI infrastructure to be able to deploy AI software. Firms that have an advantage in infrastructure will also have an advantage in the ability to deploy and scale applications with AI.
Google had peddled the idea of building AI-specific infrastructure as far back as 2006, but the problem came to a boiling point in 2013. They realized they needed to double the number of datacenters they had if they wanted to deploy AI at any scale. As such, they started laying the groundwork for their TPU chips which were put into production in 2016. It’s interesting to compare this to Amazon, who in the same year, realized they needed to build custom silicon too. In 2013, they started the Nitro Program, which was focused on developing silicon to optimize general-purpose CPU computing and storage. Two very different companies optimized their efforts for infrastructure for different eras of computing and software paradigms.
Since 2016, Google has now built 6 different AI-focused chips, TPU, TPUv2, TPUv3, TPUv4i, TPUv4, and TPUv5. Google primarily designed these chips, with varying amounts of mid and back-end collaboration from Broadcom. These chips were all fabricated by TSMC. Since TPUv2, the chips have also utilized HBM memory from Samsung and SK Hynix. While Google’s chip architecture is interesting and something we will dive into later in this report, there is a far more important topic at play.
Google has a near-unmatched ability to deploy AI at scale reliably with low cost and high performance. With that said, let’s bring some rationality to the argument, as Google has also made disingenuous claims related to chip-level performance, which need to be corrected. We believe Google has a performance/total cost of ownership (perf/TCO) advantage in AI workloads versus Microsoft and Amazon due to their holistic approach from microarchitecture to system architecture. The ability to commercialize generative AI to enterprises and consumers is a different discussion.
The realm of technology is a perpetual arms race, with AI being the swiftest-moving battlefield. The model architectures that were trained and deployed have shifted significantly over time. The case and point is with Google’s internal data. There was a swift rise in CNN models from 2016 to 2019, but then they fell again. CNNs have a very different profile of computation, memory accesses, networking, etc vs DLRMs vs Transformers vs RNNs. The same happened with RNNs which were completely displaced by transformers.

As such, hardware must be flexible to the developments of the industry and support them. The underlying hardware cannot over-specialize on any specific model architecture, or it will risk becoming obsolete as model architectures change. Chip development to large-scale volume deployment generally takes 4 years, and as such, the hardware can be left behind by what software wants to do on it. This can already be seen with certain AI accelerator architectures from startups that used a specific model type as their optimization point. This is one of the many reasons why most AI hardware startups have/will fail.
The point is especially clear with Google’s own TPUv4i chip, which was designed for inference, yet cannot run inference on Google’s best models such as PaLM. The last-generation Google TPUv4 and Nvidia A100 could not have possibly been designed with large language models in mind. Similarly, the recently deployed Google TPUv5 and Nvidia H100 could not have been designed with the AI Brick Wall in mind, nor the new model architecture strategies that have been developed to address it. These strategies are a core part of GPT-4’s model architecture.

Hardware architects have to make their best guess about the direction in which machine learning was headed for the chips they are designing. This includes memory access patterns, tensor sizes, data reuse structures, arithmetic density vs networking overhead, and more.
Furthermore, the chip microarchitecture is a fraction of the true cost of AI infrastructure. System-level architecture and deployment flexibility are far more important factors. Today we want to dive into Google’s TPU microarchitecture, system architecture, deployment slicing, scalability, and their tremendous advantage in infrastructure versus the other tech titans. This includes our thinking in a TCO model comparing the cost of Google’s AI infrastructure vs that of Microsoft, Amazon, and Meta.
We will also be directly comparing Google’s architecture to Nvidia’s, which is top of mind, especially from a performance and networking standpoint. We will also briefly compare this to AI hardware from other firms, including AMD, Intel, Graphcore, Amazon, Sambanova, Cerebras, Enflame, Groq, Biren, Iluvatar, and Preferred Networks.
We will also examine this from a practitioner’s lens for large model research, training, and deployment. We also want to dive into DLRM models, which are often under-discussed despite currently being the largest at-scale AI model architecture. Furthermore, we will discuss the infrastructure differences between DLRM and LLM model types. Lastly, we will discuss Google’s ability to succeed with TPU for external cloud customers. Also at the end, there’s an easter egg of an anomaly with Google’s TPU that we believe is an error.
Google’s System Infrastructure Advantage
Part of Google’s advantage in infrastructure it that they have always designed TPU’s from a system-level perspective. This means the individual chip is important, but how it can be used together in a system in the real world is far more important. As such, we will go layer by layer from system architecture to deployment use to chip level in our analysis.
While Nvidia also thinks from a systems perspective, their scale of a system has been smaller and more narrow than Google’s. Furthermore, until recently, Nvidia had no experience with cloud deployments. One of Google’s biggest innovations in its AI infrastructure is the use of a custom networking stack between TPUs, ICI. This link is low latency and high performance relative to costly Ethernet and InfiniBand deployments. It is more analogous to Nvidia’s NVLink.
Google’s TPUv2 could scale to 256 TPU chips, the same number as Nvidia’s current generation H100 GPU. They increased this number to 1024 with TPUv3 and to 4096 with TPUv4. We would assume that the current generation TPUv5 can scale up to 16,384 chips without going through inefficient ethernet based on the trendline. While this is important from the perspective of performance for large-scale model training, more important is their ability to divide this up for real use.

Google’s TPUv4 systems have 8 TPUv4 chips and 2 CPUs per server. This configuration is identical to Nvidia’s GPUs which come in servers of 8 A100 or H100 with 2 CPUs per server. A single server is generally the unit of compute for GPU deployments, but for the TPU, the unit of deployment is a larger “slice” of 64 TPU chips and 16 CPUs. These 64 chips connect internally with the ICI network in a 4^3 cube, over direct attached copper cabling.

Beyond this unit of 64 chips, communications transfer over to the optical realm instead. These optical transceivers cost more than 10x that of passive copper cables, so Google optimized their slice size for this 64 number to minimize system-level cost from a networking standpoint.
Compare this to a 2023 Nvidia SuperPod deployment which maxes out 256 GPUs with NVLink, 16 times smaller than the 2020 TPUv4 pod of 4096 chips. Furthermore, Nvidia clearly pays significantly less attention to density and networking costs based on Nvidia’s 1st party renders and DGX Superpod systems. Nvidia’s deployments are generally 4 servers per rack.
Beyond the realm of 4 servers with 32 total GPUs, generally, the communications must go optical. As such, Nvidia requires significantly more optical transceivers for large-scale deployments.
Google OCS
Google deployed its custom optical switch, which uses arrays of mems-based micro-mirror arrays for switching between 64 TPU slices. The quick summary is that Google claims their custom network improves throughput by 30%, use 40% less power, incurs 30% less Capex, reduces flow completion by 10%, and delivers 50x less downtime across their network, for more detailed why and how, see this report.
Google uses these OCS to make its datacenter spine. They also use them to inter and intraconnect TPU pods together. The big advantage of this OCS is that signals remain only in the optical domain from any 64 TPU slice to any other TPU slice within the 4096 TPU Pod.
Compare this to an Nvidia GPU deployment of 4,096 GPUs with multiple Nvidia SuperPods. This system would require multiple layers of switching between these GPUs, and a total of ~568 InfiniBand switches. Google only requires 48 of their optical switches for their 4096 TPU deployment.
It should be noted that Google’s OCS are also about 3.2x to 3.5x more expensive per switch, when purchased directly from Google’s contract manufacturer compared to Nvidia’s InfiniBand switches when purchased by a third party from Nvidia. This is not a fair comparison, though, given it includes Nvidia’s ~75% datacenter gross margin.
If we compare only contract manufacturing costs alone, IE cost to Google versus the cost to Nvidia; then the cost differential rises to 12.8x to 14x that of Nvidia InfiniBand switches. The number of switches required for the deployment of 4096 chips is 48 vs 568, IE is 11.8x. Nvidia’s solution is cheaper to manufacture on a switch basis. When the cost of the additional optical transceivers is included, this equation equalizes or shifts in the favor of Google.
Each connection between each layer of switching is another point that necessitates more cabling. While some of this can be done over direct attached copper cables, there are still multiple points where the signal would also need to travel over optical. Each of those layers would convert from electrical to optical to electrical between each layer of switching. This would drive power consumption for a large-scale electrical switching system much higher than that of Google’s OCS.
Google claims all these power and cost savings are so large that their networking cost is <5% of the total TPU v4 supercomputer capital costs and <3% of total power. This isn’t done just by moving from electrical to in-house optical switches.
Minimizing Network Cost Through Topology
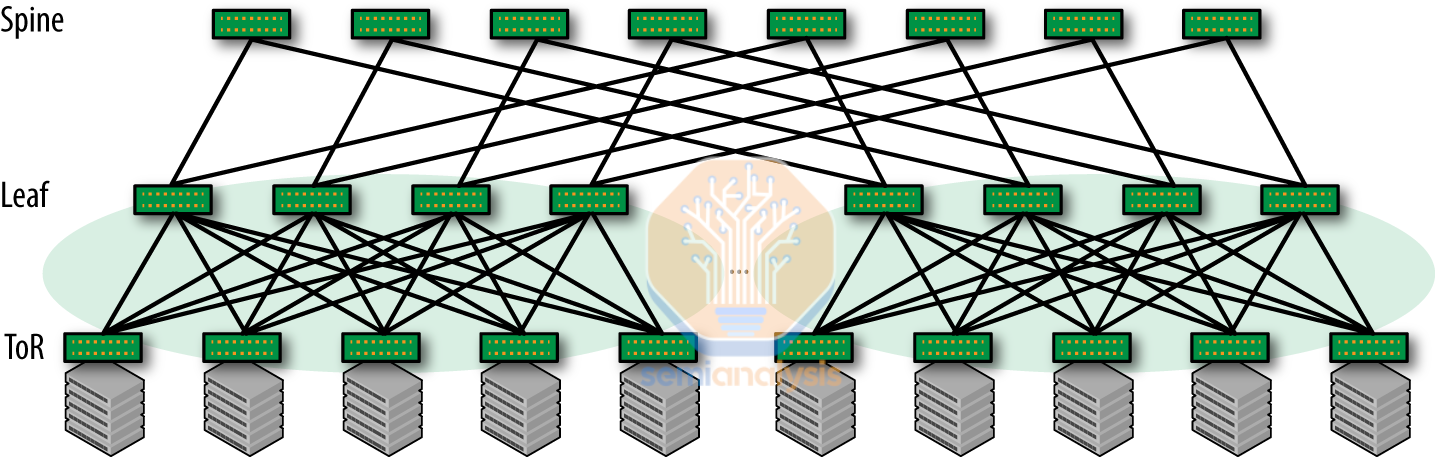
While Google pushes this viewpoint heavily, it is important to recognize that the topology of the Nvidia and Nvidia networks is entirely different. Nvidia systems deploy “Clos networks” which are “non-blocking”. This means they can establish full bandwidth connections between all input and output pairs simultaneously without any conflicts or blocking. This design provides a scalable approach for connecting many devices in a data center, minimizing latency, and increasing redundancy.
Google’s TPU networking forgoes this. They use a 3D torus topology to connect nodes in a three-dimensional grid-like structure. Each node is connected to its six neighboring nodes in a grid (up, down, left, right, front, and back), forming a closed loop in each of the three dimensions (X, Y, and Z). This creates a highly interconnected structure, where the nodes form a continuous loop in all three dimensions.
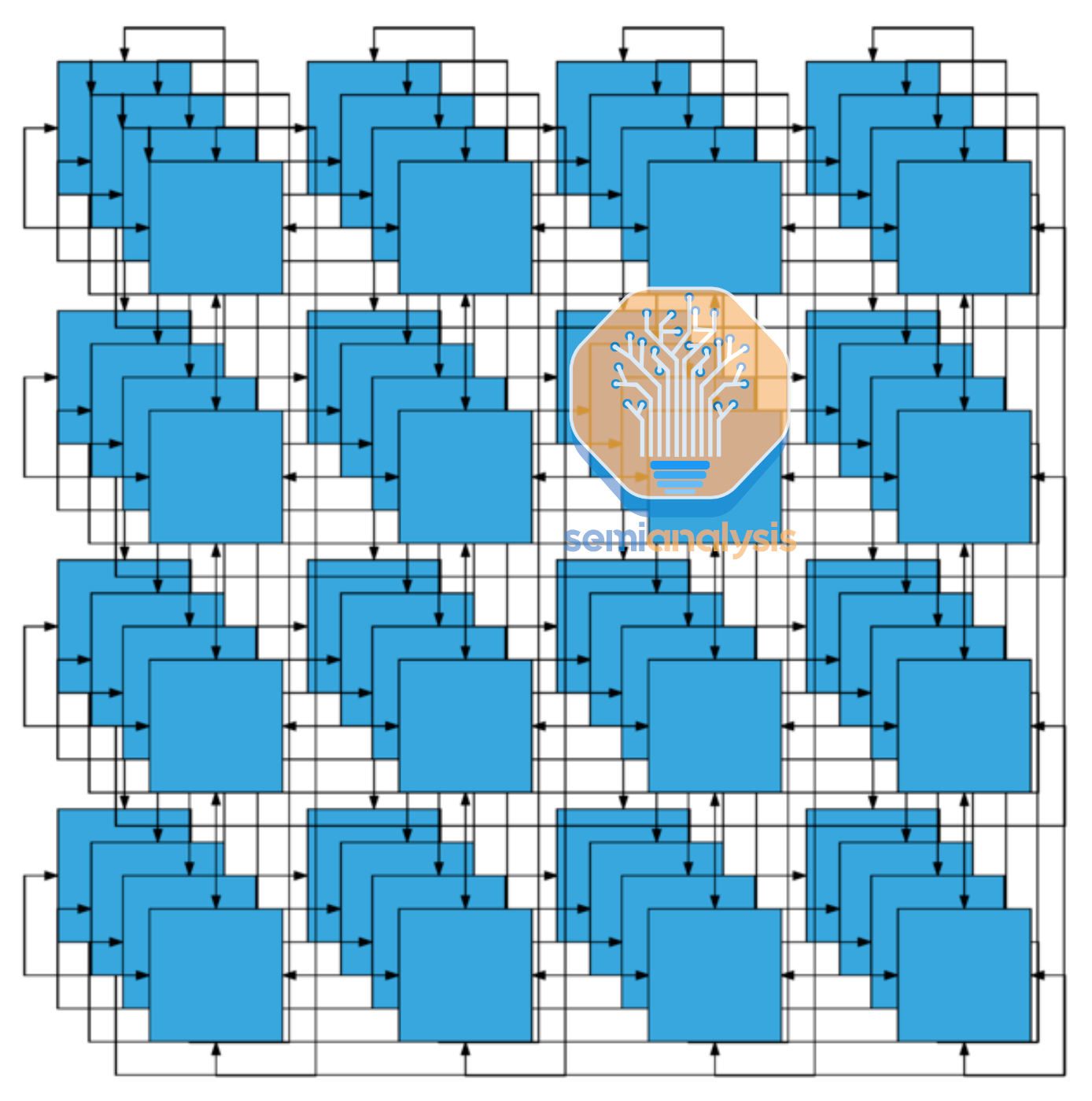
The first image is more logical, but if you think about it for a while and are a bit hungry, this network topology is literally a doughnut!
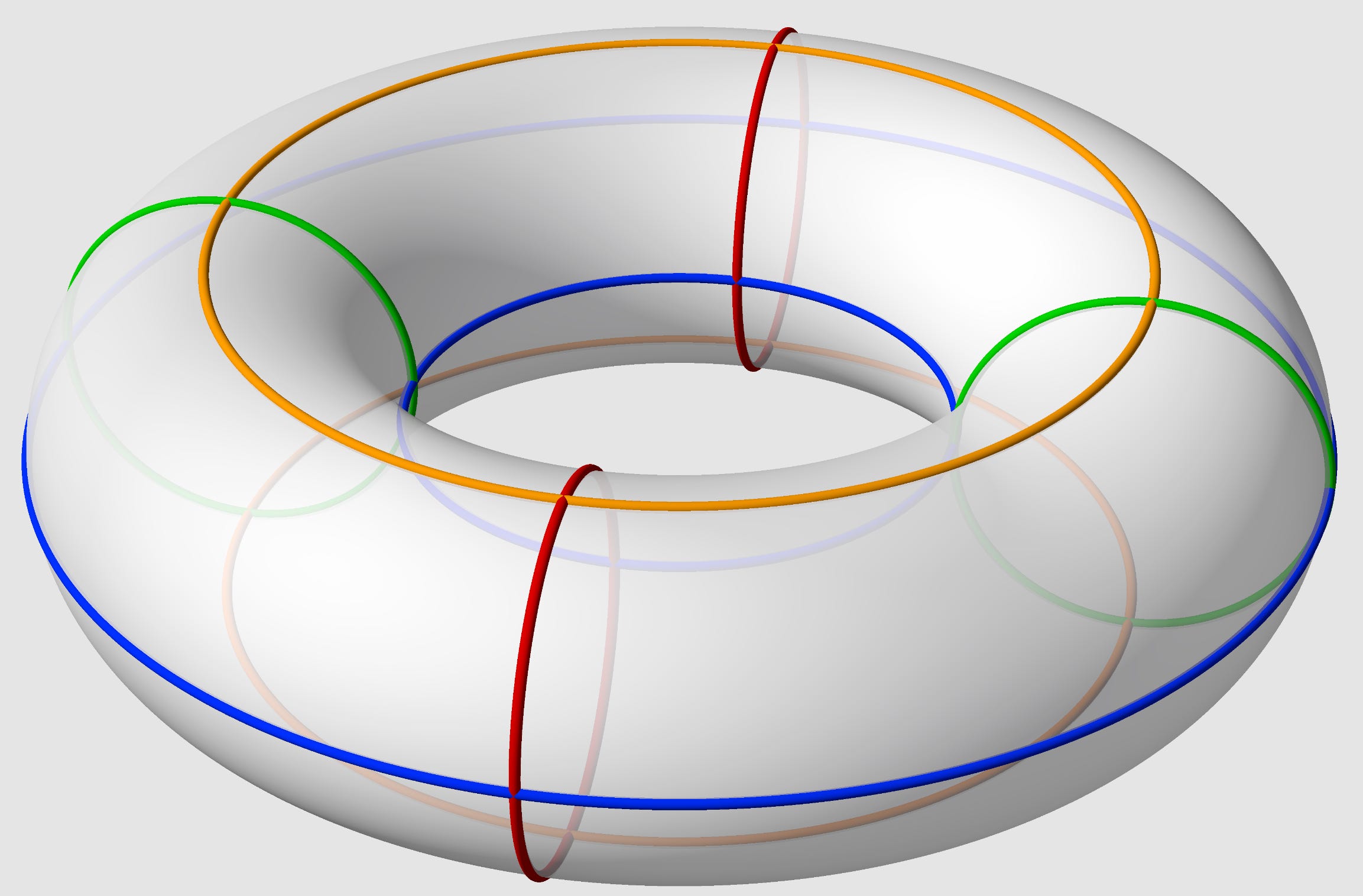
The torus topology has several advantages versus the Clos topology that Nvidia utilizes:
Lower latency: The 3D torus topology can provide lower latency due to its short, direct links between neighboring nodes. This is particularly useful when running tightly-coupled, parallel applications that require frequent communication between nodes, such as some types of AI models.
Better locality: In a 3D torus network, nodes that are physically close to each other are also logically close, which can lead to better data locality and reduced communication overhead. While latency is one aspect, power is also a tremendous benefit.
Lower network diameter: The 3D torus topology has a lower network diameter than Clos networks for the same number of nodes. There are tremendous cost savings due to requiring significantly fewer switches relative to Clos networks.
On the flip side of the coin, there are many disadvantages to the 3D torus network.
Predictable performance: Clos networks, especially in data center environments, can provide predictable and consistent performance due to their non-blocking nature. They ensure that all input-output pairs can be connected simultaneously at full bandwidth without conflicts or blocking, which is not guaranteed in a 3D torus network.
Easier to scale: In a spine-leaf architecture, adding new leaf switches to the network (to accommodate more servers, for example) is relatively simple and does not require major changes to the existing infrastructure. In contrast, scaling a 3D torus network may involve reconfiguring the entire topology, which can be more complex and time-consuming.
Load balancing: Clos networks offer more paths between any two nodes, which allows for better load balancing and redundancy. While 3D torus networks also provide multiple paths, the number of alternative paths in Clos networks can be higher, depending on the network's configuration.
Overall, while Clos has advantages, Google’s OCS mitigates many of these. OCS enables simple scaling between multiple slices and multiple pods.
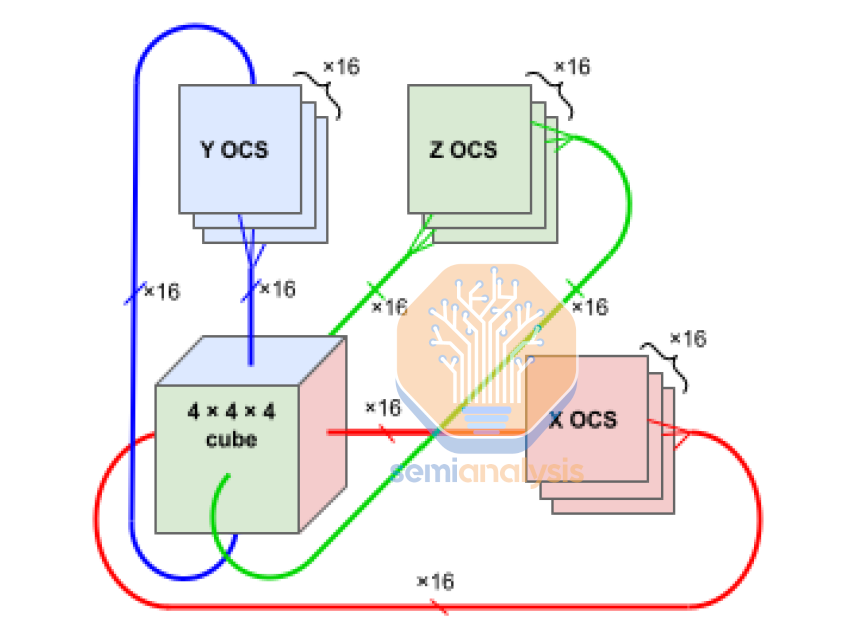
The biggest issue facing 3D torus topologies is that errors can be a bigger issue. Errors can crop up and do. Even with 99% host availability, a slide of 2,048 TPUs would have near 0 ability to work properly. Even at 99.9%, a training run with 2,000 TPUs has 50% goodput without Google’s OCS.
The beauty of OCS is that it enables routing to be reconfigured on the fly.
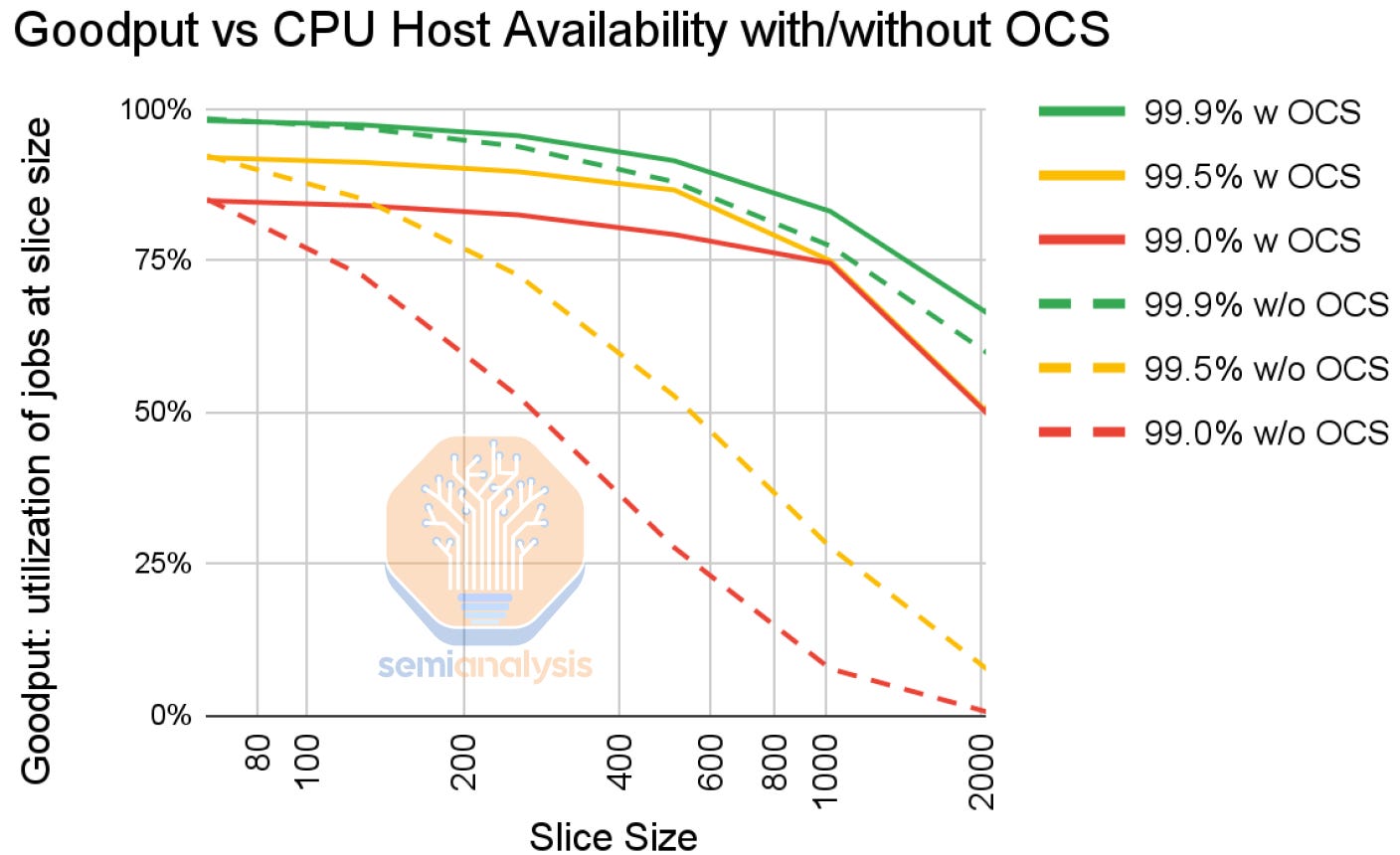
Spares are needed to allow scheduling jobs despite some failed nodes. An operator cannot realistically schedule two 2k node slices from 4k node pod without risking failures. Nvidia-based training runs often require excessive overhead dedicated to checkpointing, pulling failed nodes, and restarting them. Google simplifies this to some extent by just routing around failed nodes rather.
One other benefit of the OCS is that slices can be used as soon as they are deployed rather than waiting for the full network.
Deploying Infrastructure – A User’s Perspective
The infrastructure efficiencies are nice from a cost and power perspective, allowing Google to deploy more TPU per $ than other firms can deploy GPU, but this means nothing for use. One of the biggest advantages Google’s internal users get to experience is that they can tailor their infrastructure demands to their model.
No chip or system is ever going to match the memory, network, and types of compute profile that all users will want. Chips have to generalize, but at the same time, users want that flexibility, and they don’t want a 1 size fits all solution. Nvidia addresses this by offering many different SKU variations. Furthermore, they offer some different memory capacity tiers as well as tighter integration options such as Grace + Hopper and NVLink Network for SuperPods.
Google cannot afford this luxury. Each additional SKU means that the total deployed volume per individual SKU is lower. This in turn, reduces their utilization rates across their infrastructure. More SKUs would also mean it is harder for users to get the type of compute they want when they want it because certain options will inevitably be oversubscribed. Those users would then be forced to use a suboptimal configuration.
As such, Google has a tough problem feeding their researchers the exact products they want while also minimizing SKU variation. Google has exactly 1 TPUv4 deployment configuration of 4,096 TPU’s, in comparison to hundreds of different size deployments and SKUs that Nvidia must support for their larger, more varied customer base. Despite this, Google is still able to slice and dice this in a unique way that enables internal users to have the flexibility of infrastructure they desire.
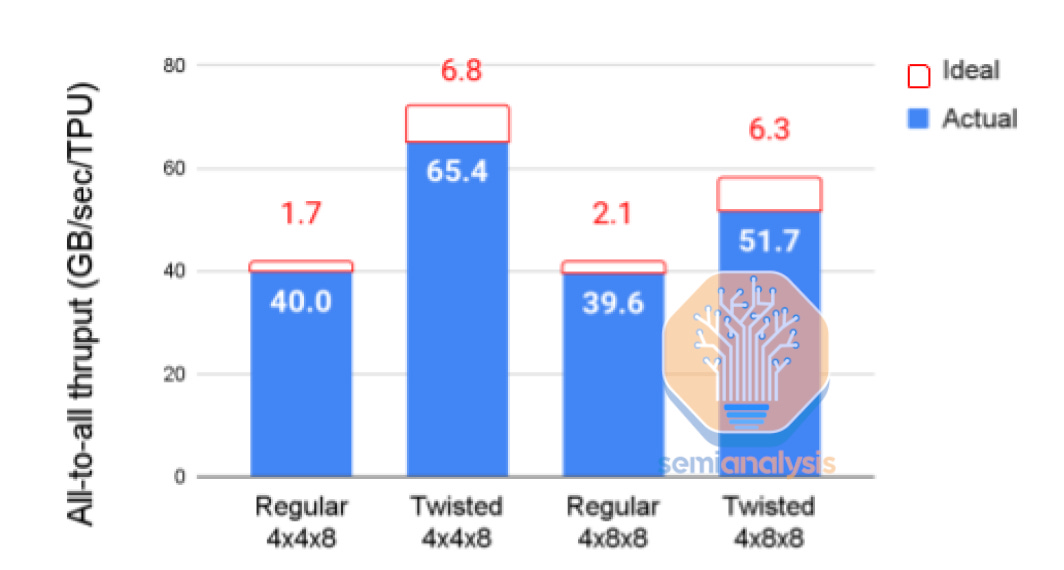
Google’s OCS also enables the creation of custom network topologies such as twisted torus networks. These are 3d torus networks where some dimensions are twisted, meaning that nodes at the edges of the network are connected in a non-trivial, non-linear manner, creating additional shortcuts between nodes. This further improves network diameter, load balancing, and performance.
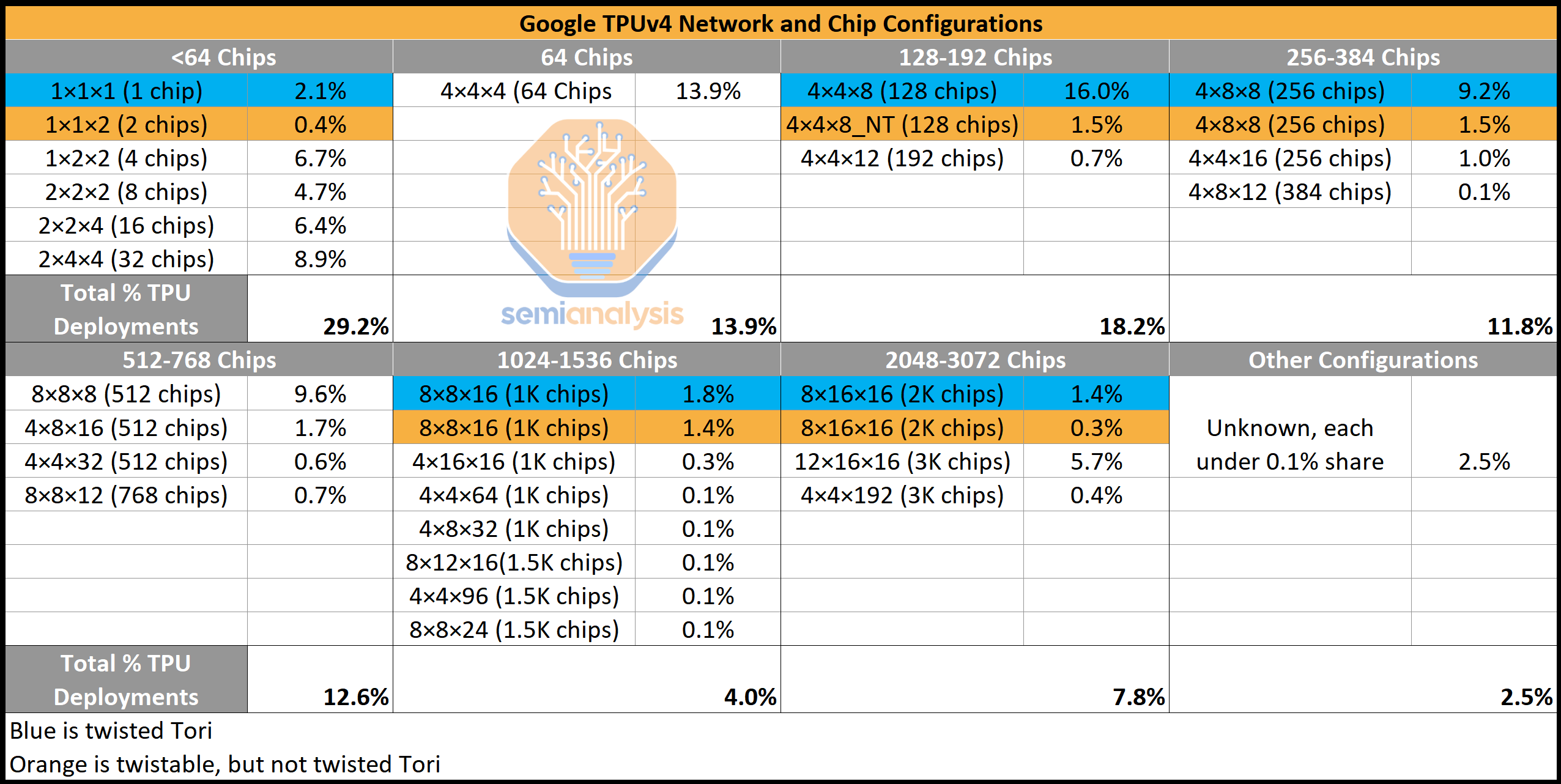
Google’s teams take advantage of this heavily to assist with certain model architectures. Below is a snapshot of the popularity of various TPU configurations by the number of chips and network topology for just 1 day in November 2022. There are more than 30 different configurations, despite many having the same number of chips in the system, to suit a variety of model architectures that are being developed. This is tremendous powerful insight from Google on their use of TPUs and flexibility. Furthermore, they also have many less-used topologies that are not even pictured.
To take full advantage of the bandwidth available, users map data parallelism along one dimension of the 3D torus and the two model parallel parameters on the other dimensions. Google claims optimal topology selection enables 1.2x to 2.3x higher performance.
We will discuss the software stack and external users later in this report.
The Largest At Scale AI Model Architecture: DLRM
Any discussion of AI infrastructure is incomplete without discussing Deep Learning Recommendation Models (DLRMs). These DLRMs are the backbone of companies like Baidu, Meta, ByteDance, Netflix, and Google. It is the engine of over a trillion dollars of annual revenue in advertising, search ranking, social media feed ordering, etc. These models consist of billions of weights, training on more than a trillion examples and handling inference at over 300,000 queries per second. The size of these models (10TB+) and far exceeds that of even the largest transformer models, such as GPT4, which is on the order of 1TB+ (model architecture differences).
The common thread between all of the firms mentioned above is that they rely on constantly updated DLRMs to drive their businesses of personalizing content, products, or services in various industries, such as e-commerce, search, social media, and streaming services. The cost of these models is tremendous, and hardware must be co-optimized to it. DLRMs have not been static, but they have been constantly improving over time, but let’s explain the general model architecture before moving forward. We will try to keep it simple.
DLRM aims to learn meaningful representations of user-item interactions by modeling both categorical and numerical features. The architecture is comprised of two main components: the Embedding Component (dealing with categorical features) and the Multilayer Perceptron (MLP) Component (handling numerical features).
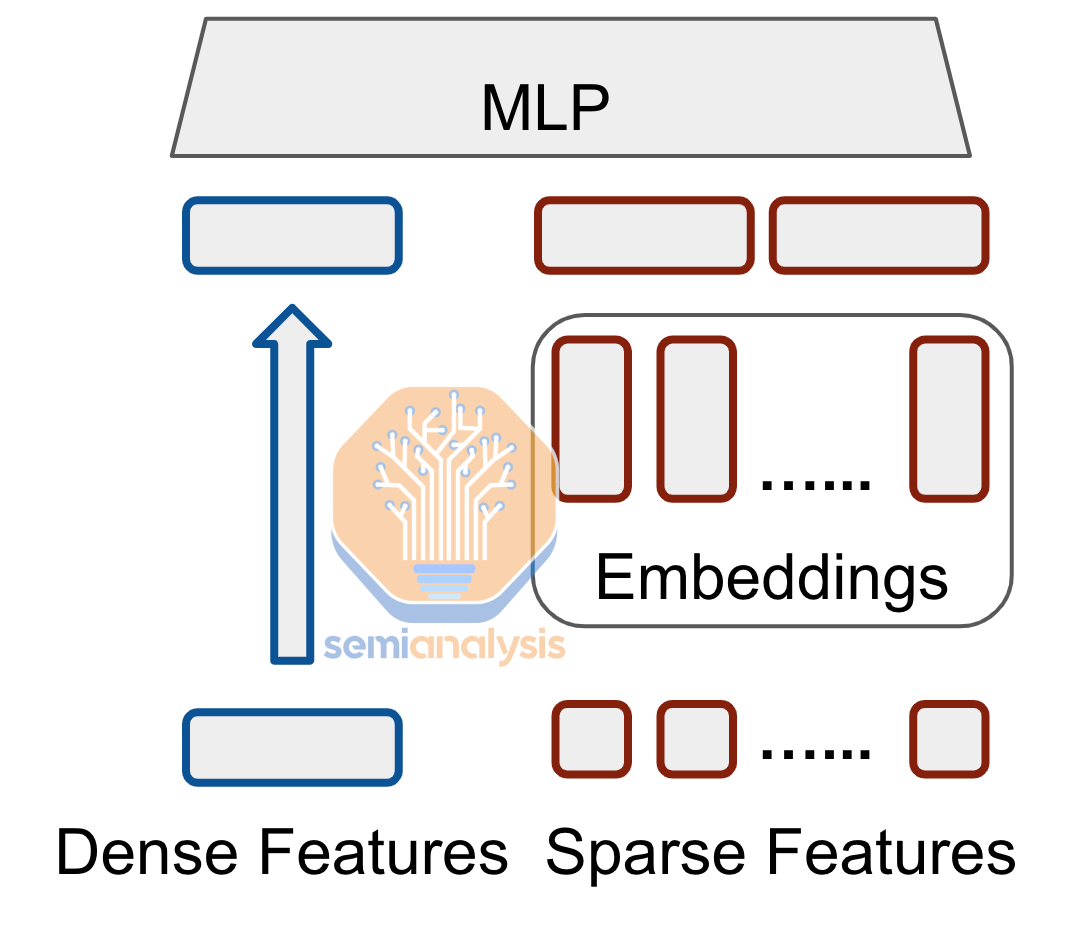
In the most simplified terms, the multilayer perceptron component is dense. The features are fed into a series of fully connected layers. This is similar to older pre-GPT 4 transformer architectures, which were also dense. The dense layers map very well to massive matrix multiple units on hardware.
The embedding component is highly unique to DLRMs and the one that makes its computational profile so unique. DLRM inputs are categorical features represented as discrete, sparse vectors. A simple Google search only contains a few words out of the entire language. These sparse inputs do not map well to massive matrix multiply units found in hardware since they are fundamentally more akin to hash tables, not tensors. Since neural networks usually perform better on dense vectors, embeddings are employed to convert categorical features into dense vectors.
Sparse input: [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
Dense vector: [0.3261477, 0.4263801, 0.5121493]
Embedding functions map the categorical space (words in the English language, engagement with a social media post, behavior towards a type of post) to a smaller, dense space (100-vectors representing each word). These functions are implemented using lookup tables, which are an essential part of DLRMs and often form the first layer of DLRM models. The size of embedding tables can vary significantly, ranging from tens of megabytes to hundreds of gigabytes or even terabytes each.
Meta’s 2-year-old DLRM was over 12 trillion parameters and required 128 GPUs to run inference. Nowadays, the largest production DLRM model are at least multiple times larger and consumes over 30TB of memory just to hold the model embeddings. Expectations are that this increases to over 70TB of embeddings over the next year! As a result, these tables need to be partitioned across the memory of many chips. There are three primary partitioning methods: column sharding, row sharding, and table sharding.
The performance of DLRMs is largely gated by the memory bandwidth, memory capacity, vector processing performance, and the networking/interconnect between chips. Embedding lookup operations primarily consist of small gather or scatter memory accesses, which have low arithmetic intensity (FLOPS do not matter at all). The accesses to the embedding tables are fundamentally unstructured sparsity. Every query must pull data from part of the 30TB+ of embeddings, sharded across hundreds or thousands of chips. This can lead to imbalances in computation, memory, and communication loads across a supercomputer for DLRM inference.
This differs greatly for dense operations in MLPs and GPT-3-like transformers. Chip FLOPS/sec are still relevant as one of the primary performance drivers. Of course, there are a variety of factors holding performance back beyond FLOPs, but GPUs can still achieve over 71% hardware flops utilization in Chinchilla-style LLMs.
Google’s TPU Architecture
Google's TPU introduces some key innovations to the architecture, which set it apart from other processors. Unlike traditional processors, the TPU v4 doesn't have a dedicated instruction cache. Instead, it employs a Direct Memory Access (DMA) mechanism, similar to the Cell processor. The vector caches in TPU v4 are not part of a standard cache hierarchy but are utilized as scratchpads. Scratchpads differ from standard caches in that they require manual writing, while standard caches handle data automatically. Google can utilize this more efficient infrastructure due to not needing to serve as large of a general-purpose compute market. This does affect the programming model somewhat, although Google engineers believe the XLA compiler stack handles this well. The same cannot be said for external users.
The TPU v4 boasts 160MB SRAM for the scratchpad along with 2 TensorCores each of which has 1 Vector Unit with 4 Matrix Multiply Units (MXUs) and 16MB Vector Memory (VMEM). The two TensorCores share 128MB of memory. They support 275 TFLOPS of BF16 and also support INT8 data types. The memory bandwidth of the TPU v4 is 1200GB/s. The Inter Chip Interconnect (ICI) provides a data transfer rate of 300GB/s via six 50GB/s links.
A 322b Very Long Instruction Word (VLIW) Scalar Computation Unit is included in the TPU v4. In VLIW architectures, the instructions are grouped together into a single, long instruction word, which is then dispatched to the processor for execution. These grouped instructions, also known as bundles, are explicitly defined by the compiler during program compilation. The VLIW bundle comprises up to 2 scalar instructions, 2 vector ALU instructions, 1 vector load and 1 vector store instruction, and 2 slots for transferring data to and from the MXUs.
The Vector Processing Unit (VPU) is equipped with 32 2D registers, containing 128x 8 32b elements, making it a 2D vector ALU. The Matrix Multiply Units (MXUs) are 128x128 on v2, v3, and v4, with the v1 version featuring a 256x256 configuration. The reason for this change was that Google simulated that four 128x128 MXUs have 60% higher utilization than one 256x256 MXU yet the four 128x128 MXUs take up the same amount of area as the 256x256 MXU. The MXU inputs utilize 16b Floating Point (FP) inputs and accumulate with 32b floating point (FP).
These larger units allow more efficient data reuse to break through the memory wall.
Google DLRM Optimizations
Google was one of the first to start using DLRMs at scale with their search product. This unique need led to a very unique solution. The above architecture described has a major deficiency in that it cannot effectively handle the embeddings of a DLRM. Google’s main TensorCore is very large and does not match the computational profile of these embeddings. Google had to develop an entirely new type of ”SparseCore” in their TPU which is different than the “TensorCore” for dense layers, which was described above.
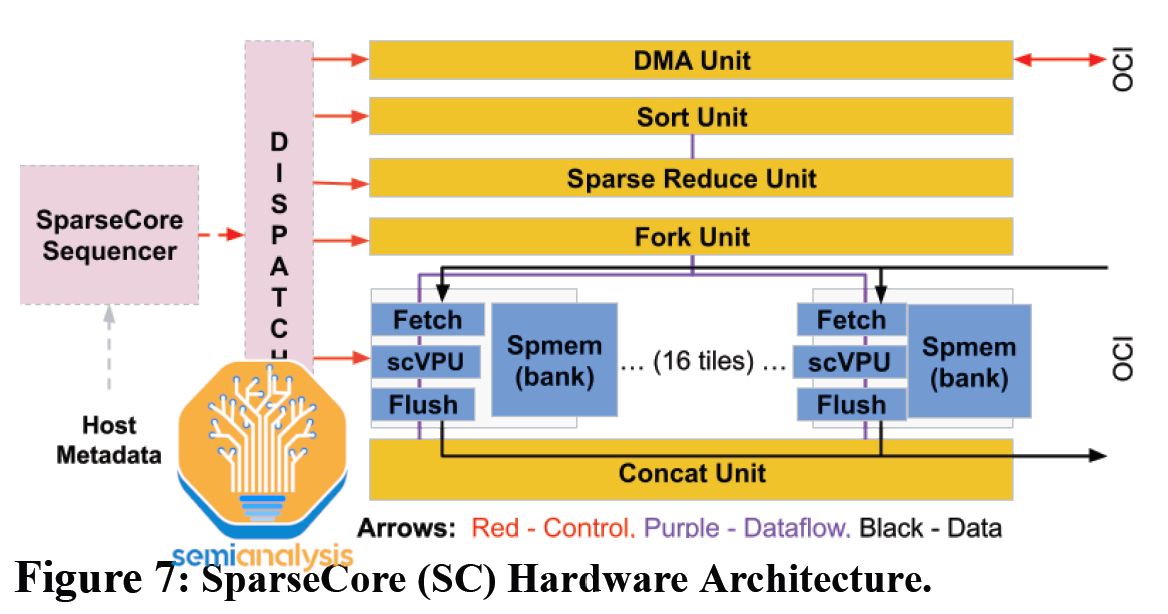
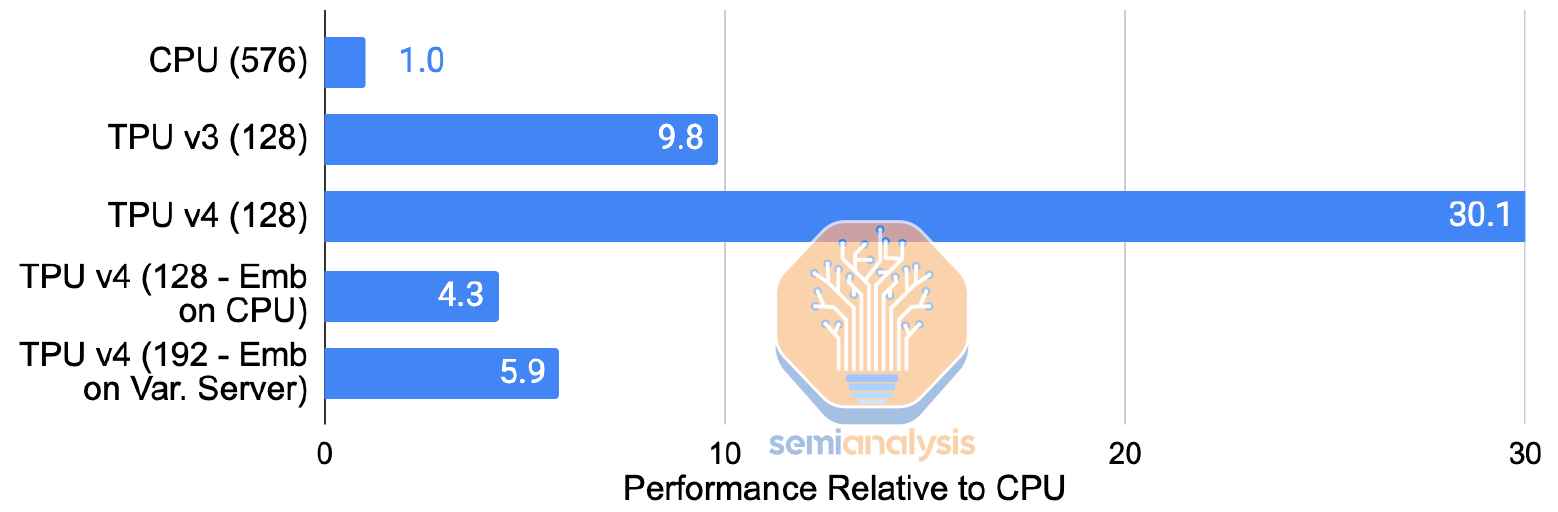
The SparseCore (SC) provides the hardware support for embeddings in Google’s TPU. From as early as TPU v2, these domain-specific processors have tiles directly tied to each HBM channel/sub-channel. They accelerate the most memory bandwidth-intensive part of training Deep Learning Recommendation Models (DLRM) while only taking up about 5% of die area and power. By using the fast, HBM2 on each TPU v4 chip for embeddings, rather than CPUs, Google showed a 7x speedup of their internal production DLRM compared to leaving embeddings on the host CPU’s main memory (TPU v4 SparseCore vs TPU v4 Embeddings on Skylake-SP).
SparseCore enables fast memory access from HBM, with dedicated fetch, processing, and flush units to move data to banks of Sparse Vector Memory (Spmem) and updated by a programmable 8-wide SIMD Vector Processing Unit (scVPU). 16 compute tiles of these units go into a SparseCore.
Additional cross-channel units perform specific embedding operations (DMA, Sort, Sparse Reduce, Fork, Concatenate). There are 4 SparseCores per TPU v4 chip, each with 2.5MB of Spmem. Going forward, we speculate that the number of SparseCores continues to increase to 6 for TPUv5 and the number of tiles to increase to 32 due to the increased number of sub-channels on HBM3.
While the performance gain from moving to HBM is massive, performance scaling is still affected by interconnect bisection bandwidth. The new 3D torus of the ICI in TPU v4 helps scale embedding lookup performance further. However, the improvement drops off when scaling up to 1024 chips as SparseCore overheads become the bottleneck.
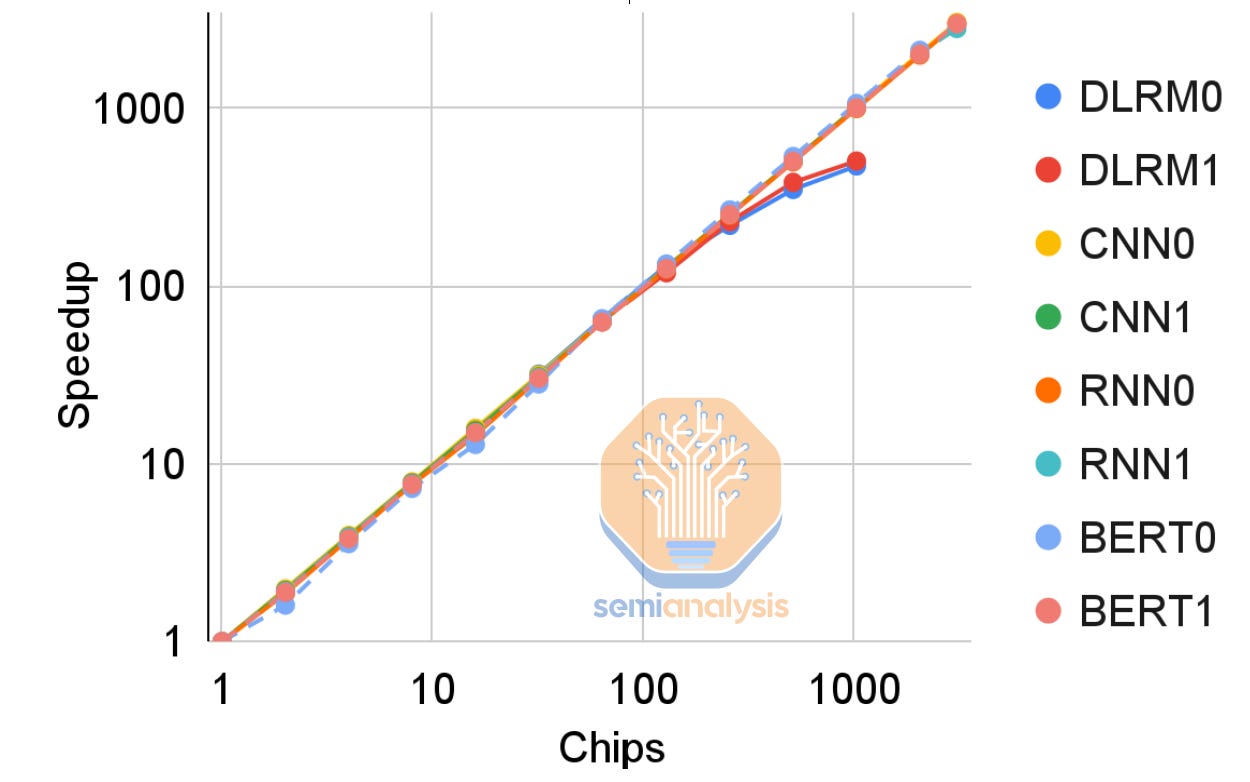
This bottleneck likely results in Spmem per tile also increasing with TPUv5 if Google feels their DLRMs need to increase in size and capacity beyond that of ~512 chips.
The rest of this report will compare the Google TPU to Nvidia GPUs with real-world data for large language model training, not just the typical comparison of small models that are not relevant to training budgets that you typically see.
It will also compare the microarchitecture to Nvidia GPUs, as well as to other AI hardware from AMD, Intel, Graphcore, Amazon, Sambanova, Cerebras, Enflame, Groq, Biren, Iluvatar, and Preferred Networks.
We will also compare other tech titans’ infrastructure costs for AI versus Google’s. Lastly, there’s also a weird anomaly with Google’s TPU that we have to assume is an error.