

Amazon’s Cloud Crisis: How AWS Will Lose The Future Of Computing
Amazon’s Cloud Crisis: How AWS Will Lose The Future Of Computing
Nitro, Graviton, EFA, Inferentia, Trainium, Nvidia Cloud, Microsoft Azure, Google Cloud, Oracle Cloud, Handicapping Infrastructure, AI As A Service, Enterprise Automation, Meta, Coreweave, TCO

Amazon owns more servers than any other company in the world despite its internal needs being much smaller than Google, Microsoft, Meta, and Tencent. Amazon Web Services (AWS) has long been synonymous with cloud computing. AWS has dominated the market by catering to startups and businesses alike, offering scalable, reliable, low-cost compute, and storage solutions. This engine has driven Amazon to become the preeminent computing company in the world, but that is changing.
Amazon is an amazing technical company, but they lack in some ways. Technological prowess, culture, and/or business decisions will hamper them from capturing the next wave of cloud computing like they have the last two. This report will cover these 3 phases of cloud computing and how Amazon’s continued dominance in the first two phases doesn’t necessarily give them a head start in the battle for the future of computing.
We will present an overview of Amazon’s various in-house semiconductor designs, including Nitro, Graviton, SSDs, Inferentia, and Trainium. This overview will tackle the technology and total cost of ownership perspectives of Amazon’s in-house semiconductor ambitions. We will also cover what Amazon is intentionally doing that harms its position in AI and enterprise automation and will ultimately cause them to lose market share in computing. We will also explain how Microsoft Azure, Google Cloud, Nvidia Cloud, Oracle Cloud, IBM Cloud, Equinix Fabric, Coreweave, Cloudflare, and Lambda are each fighting Amazon’s dominance across multiple vectors and to various degrees.
Before we dive into our thesis, we need a bit of a history lesson first.
The Emergence of AWS
As Amazon ballooned in size with its retail business, it began to run into limitations of its monolithic 90s-era software practices. Metcalfe’s law sort of applied; as each additional service or developer was added, complexity grew at an n^2 rate. Even simple changes or enhancements impacted many downstream applications and use cases, requiring huge amounts of communication. As such, Amazon would have to freeze most code changes at a certain point in the year so the holiday season could focus on bug fixes and stability.
Amazon also had significant issues with duplication of work and resources just to stand up a simple relational database or compute service. This was exacerbated by the fact that the brightest engineers are often not the best communicators, which especially rings true when there isn’t a shared goal among different teams. Large software projects tend to reach a critical mass where the size of the organization and applications cause productivity and new features to take way too long to implement.
Microsoft was among the first companies to have this problem, and they initially solved this by bringing in the role of program manager. A dedicated person who interfaces with a team of developers managing tasks such as organization, communications, and specification documents was unheard of at the time, but it was an effective tool. This alone doesn’t solve all of the problems.
Amazon reached this same issue many years later, but they took a very different approach when they ran into these issues. Instead of facilitating communications between teams, Amazon attempted to reduce communications by leveraging "hardened interfaces." They moved from this monolithic software development paradigm to a service-oriented architecture. To be clear, other companies and academia were also implementing this, but no one jumped into the technique quite as strongly as Amazon.
Steve Yegge, an early employee at Amazon, recalled this pivotal moment at Amazon. Below is a portion of a memo he had ranting about Amazon once he joined Google, which was accidentally shared online.
So one day Jeff Bezos issued a mandate. He's doing that all the time, of course, and people scramble like ants being pounded with a rubber mallet whenever it happens. But on one occasion -- back around 2002 I think, plus or minus a year -- he issued a mandate that was so out there, so huge and eye-bulgingly ponderous, that it made all of his other mandates look like unsolicited peer bonuses.
His Big Mandate went something along these lines:
All teams will henceforth expose their data and functionality through service interfaces.
Teams must communicate with each other through these interfaces.
There will be no other form of interprocess communication allowed: no direct linking, no direct reads of another team's data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
It doesn't matter what technology they use. HTTP, Corba, Pubsub, custom protocols -- doesn't matter. Bezos doesn't care.
All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
Anyone who doesn't do this will be fired.
Thank you; have a nice day!
Ha, ha! You 150-odd ex-Amazon folks here will of course realize immediately that #7 was a little joke I threw in, because Bezos most definitely does not give a shit about your day.
The most impactful part of this rant is number 5, which is they must be able to externalize these hardened interfaces. This is the beginning of making AWS….in 2002
From there, off to the races! The logical progression was to make compute and storage hardware abstracted away in a similar manner. With many teams building services all the time and being told they will be fired if they talk to other teams, there was no conceivable way for IT centrally plan the need for servers and the growth of compute and storage requirements. As teams’ services surged in popularity internally, they needed to be able to provision hardware for the task.
It took another ~4 years to take these ideas and create the public offering that become AWS. For more history, check out this awesome podcast.
We will fast forward through the start and talk more about what this era means to this day. In the early days, Amazon picked up all the startups and enabled them to actually build their own businesses. While most early adopters were these non-traditional new firms in software like Netflix and Twitch, innovative hardware companies were also all aboard the unstoppable freight train of cloud.
It’s so much easier. For a new company like us, you would just never build a traditional data center anymore.
Andy Bechtolsheim, 2010 – Founder of Arista and Sun Microsystems, also one of earliest investors in Google and VMware.
Amazon launched S3, a storage service, in 2006. Shortly after EC2, a compute service. In 2009, a relational database service was offered. Then there was Redshift and Dynamo DB. There are quite literally hundreds of important releases Amazon did with customers before any of their competitors got even close. The main point is that this era is characterized by AWS simply having better/more products, applications, and service offerings with better documentation than anyone else. Every time Google Cloud or Microsoft Azure built something, Amazon was many steps ahead and/or easier to use.
While this was true, especially in the beginning of the cloud, and it still continues to this day in some categories. The story and life cycle of the emergence of AWS are still playing out, although the gulf has diminished significantly. Amazon’s model of letting people pay with a credit card disrupted the legacy business of 6-figure or 7-figure service contracts and continues to do so. There is a long tail to this first wave of cloud computing.
The Dominant Scale of AWS
As the middle part of the last decade rolled on, the majority of fortune 500 companies also started to migrate toward the cloud. As the cloud computing market matured, other companies recognized the opportunity and began investing heavily in their cloud offerings. Microsoft Azure, in particular, emerged as a strong contender by leveraging its enterprise-friendly approach. While Google Cloud Platform initially struggled to gain market share due to a lack of commercial focus, it has since improved its offerings and will reach profitability soon.
The competition has only gotten tougher and more serious, but Amazon has an ace up its sleeve.
Scale.
There are two ways to look at this scale advantage. First is from the lens that Amazon is quite literally just larger and has more footprint in the cloud space than anyone else. Cloud service providers needed a certain level of scale to leverage their size into buying hardware at lower prices and to amortize their software and hardware design costs.
A cloud service provider also needs to have a certain amount of capacity ready for others to use at a moment’s notice. This is especially important because cloud service providers cannot just centrally plan the utilization of their servers. Even long-term contracts often come with a high degree of uncertainty around when credits will be spent. At the same time, cloud providers must have high utilization rates to get an adequate return on invested capital (RoIC). The larger you are, the easier that is to achieve those high utilization rates with enough excess capacity for customers to ramp up and down.
This lens is mostly limited in duration as the size of the cloud market means that multiple companies can achieve a minimum viable critical mass. Amazon hit that hockey stick moment, arguably in the early to middle parts of the 2010s. In 2012, Amazon had 23 total price reductions for AWS since inception, and by 2015 they had done 51 total. Public price reductions slowed markedly after the 2017 era, despite competition starting to heat up, although private double-digit % discounting is very common. At the very least, Microsoft and Google have also long since achieved that level of scale. In specialized applications, other clouds have reached meaningful scale as well, such as Cloudflare in CDN or Oracle in AI servers.
The much more important angle of scale is from the lens of purpose-built semiconductors, either in-house or with partners in the ecosystem. Amazon and Google are the foremost leaders in this transition, but every hyperscale company has already begun deploying at least some in-house chips. This ranges from networking to general-purpose compute to ASICs.
Amazon drives tremendous savings from custom silicon which are hard for competitors to replicate, especially in the standard CPU compute and storage applications. Custom silicon drives 3 core benefits for cloud providers.
Engineering the silicon for your unique workloads for higher performance through architectural innovation.
Strategic control and lock-in over certain workloads.
Cost savings from removing margin stacking of fabless design firms.
Amazon was, and still is, run in a very entrepreneurial way when it comes to new business units, segments, or infrastructure changes. Their teams, in many ways, remain nimble and small, but they still have the full backing of the behemoth organization behind them. Our favorite story pertaining to this is their inception into custom silicon.
Amazon Nitro
All the way back in ~2012, an engineer at AWS, had an idea. Why not place a ‘dongle’, a dedicated piece of hardware, between every EC2 instance and the outside world so that all data would flow through it? This dongle would run security, networking, and virtualization tasks such as the hypervisor. The benefits of the ‘dongle’ would have the immediate benefit of improving performance, cost, and security for EC2 instances while also enabling bare metal instances. What started as a little idea was able to turn into the entire custom silicon effort of Amazon, which designs many different chips and saves them tens of billions of dollars a year.
AWS set out a specification for a custom chip that would support this dongle idea. The requirements were simple, a dual-core Arm-based System-on-Chip (SoC), that could be PCIe attached. After approaching several firms, AWS worked with Cavium on the challenge of building a custom SoC at a cost that wouldn’t lead to a material increase in the cost of each EC2 server. The resulting Cavium part was delivered soon after. The whole system, with the custom SoC on a discrete PCIe card and associated software, was named ‘Nitro System’. It first appeared (although it wasn’t initially discussed publicly) in C3, R2, and I2, EC2 instances.
By August 2022, AWS had over 20 million Nitro parts installed over four generations, with every new EC2 server installing at least one Nitro part.
The primary cost benefit of this “dongle” is that it offloads Amazon’s management software, the hypervisor, which would otherwise run on an existing CPU. The most commonly deployed CPU across Amazon’s infrastructure was, and still is, an Intel 14nm 24-core CPU. Even to this day, other clouds, such as Microsoft Azure eat as many as 4 CPU cores on workloads that aren’t the customers’. If this held true across all of Amazon’s infrastructure, that would be as much as a ~15% reduction in the number of VMs for existing servers and, therefore, revenue.
Even with much more conservative estimates of 2 CPU cores saved per Nitro, with per-core cost estimated at 1/4th that of reserved list price, the savings of Nitro exceed $7 billion annually.

The removal of these workloads from server CPU cores to the custom Nitro chip not only greatly improves cost, but also improves performance due to removing noisy neighbor problems associated with the hypervisor, such as shared caches, IO bandwidth, and power/heat budgets.
Furthermore, customers also reap the benefits of improved security by adding an air gap between the hypervisor management layer and server. This physical isolation removes a possible vector of side-channel escalation attacks from rogue tenants.
In addition to the hypervisor offload savings, as Nitro has evolved, it has also taken a central role in many networking workloads. For example, IPsec can be offloaded, which alone could be many millions in savings for each of Amazon’s major customers.
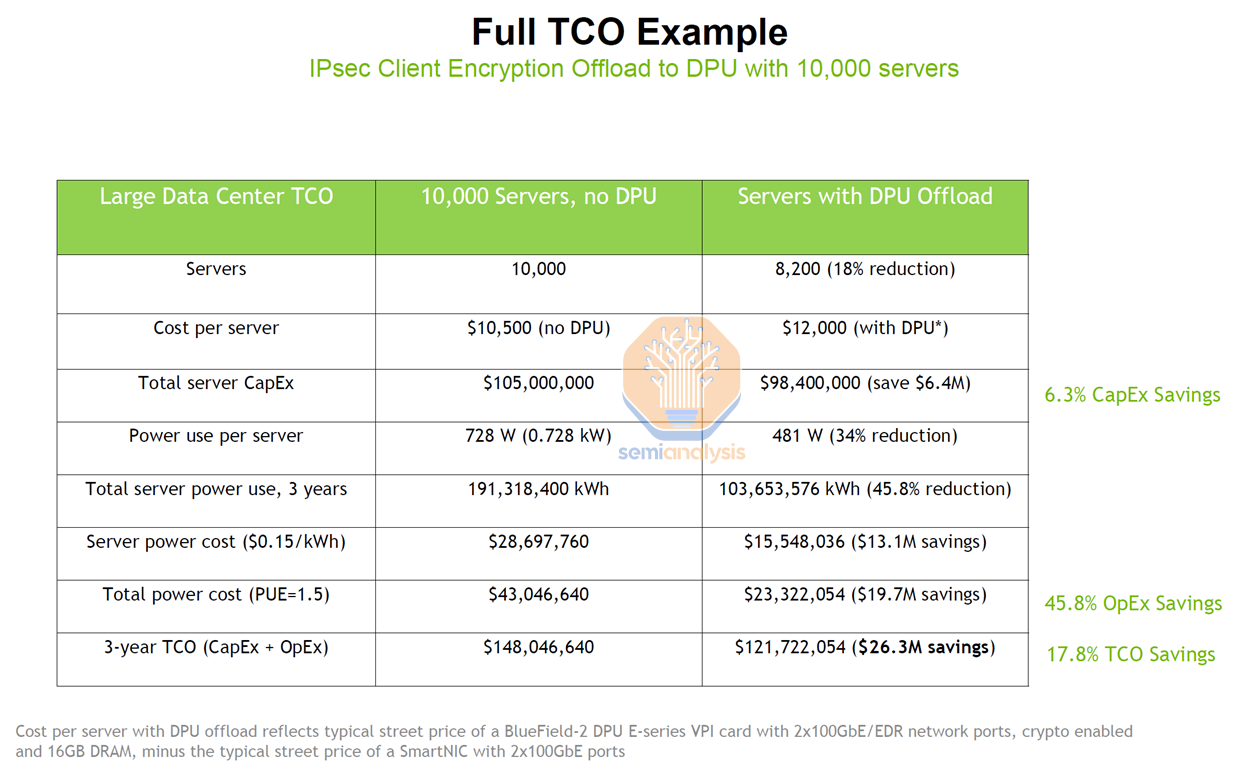
The core of Amazon’s custom silicon efforts comes directly from their work with and later acquisition of Annapurna Labs in 2015. Annapurna was focused on server SOCs for networking and storage. It should be noted that Nitro is not just 1 chip, even though we are referring to it as such. There are multiple generations with multiple variants for different use cases.
Most of Amazon’s top services beyond EC2 are related to storage and databases. Nitro is the major enabler of a durable competitive advantage for Amazon in these workloads. Classical server architectures places at least some storage within every single server, which leads to significant stranding of unused resources.
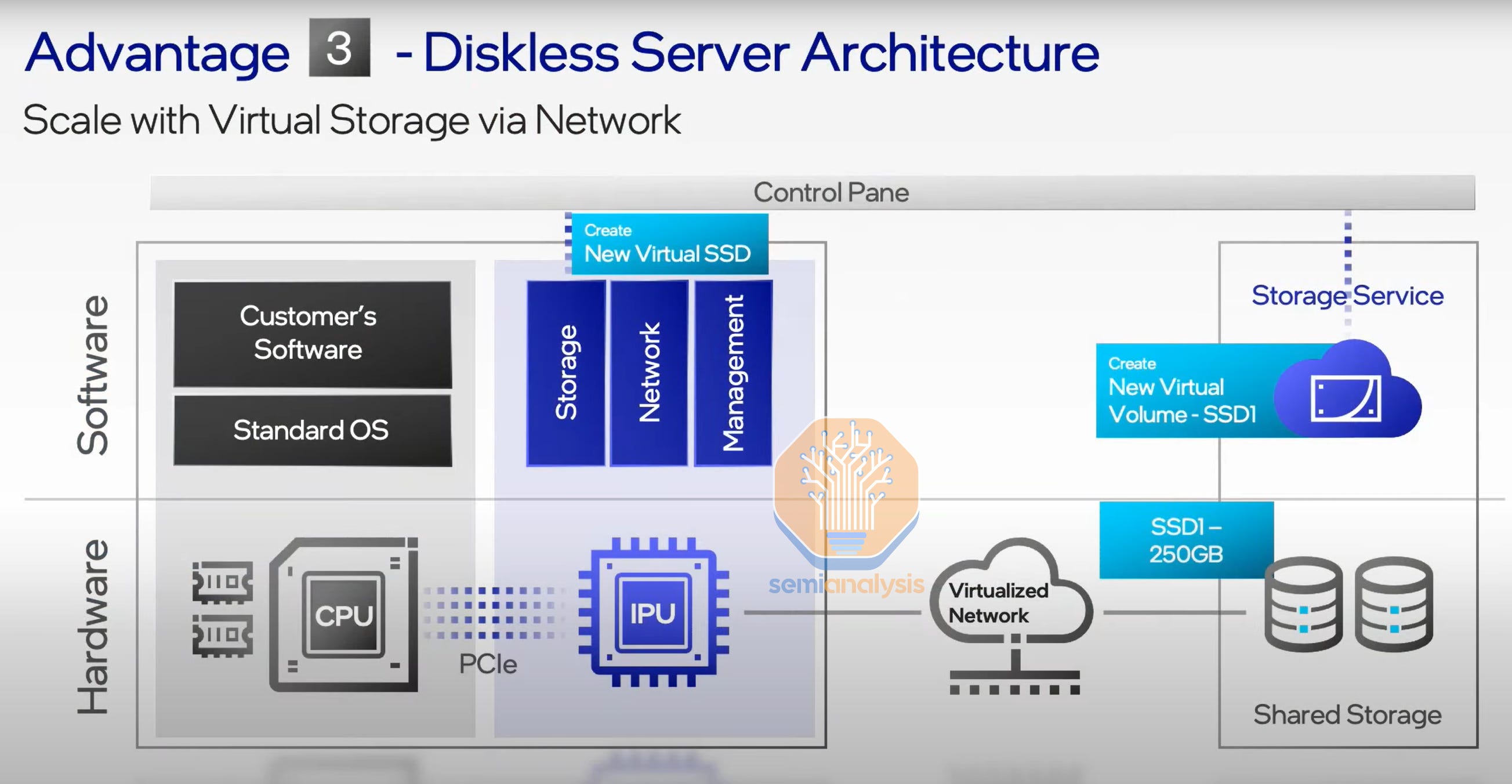
Amazon is able to remove that storage from every server and move it into centralized servers. The servers that customers rent can then boot off of the networked storage. Nitro enables this to be done even with high-performance NVMe SSDs. This shift in storage architecture helps Amazon save tremendously on storage costs as customers do not need to pay for any more storage than they want to use. Customers can dynamically grow and shrink their pools of high-performance storage seamlessly.
This is extremely costly from a compute and networking perspective using general-purpose hardware, but Nitro can provide services such as virtual disk to the tenant's virtual machines at a lower cost due to being on an in-house workload-specific ASIC.

Amazon’s focus on storage extends out to co-designing the ‘AWS Nitro SSD’ controller with Marvell. These SSDs focus on avoiding latency spikes and avoiding latency variability as well as maximizing the lifetime of the SSD through advanced, Amazon-managed wear leveling. Future variants will include some compute offload to improve query performance.
The other big 2 clouds are trying to go the same route, but they are years behind and require a partner who demands some margin. Google has chosen to go with custom silicon with the co-designed Intel Mount Evans IPUs, and Microsoft has a combination of AMD Pensando DPUs and eventually internally developed Fungible-based DPUs for storage use cases. Both of these competitors are stuck with 1st or 2nd generation merchant silicon for the next few years.
Amazon is installing their 5th generation Nitro which was designed in-house. The advantages that Nitro brings from an infrastructure cost perspective cannot be understated. It enables much lower costs for Amazon, which can then be passed on to customers, or result in higher margins. With that said, Amazon’s Nitro also has some major drawbacks; more on this later.
Arm At AWS
While Nitro does utilize Arm-based CPU cores, the key is the variety of fixed-function application-specific acceleration. AWS’s interest in Arm-based custom silicon isn’t limited to offloading their own workloads to dedicated hardware. During 2013, AWS’s thinking on using their own silicon developed much further. In a document titled “AWS Custom Hardware,” James Hamilton, an engineer, proposed two key points.
The volume of Arm CPUs being shipped on mobile and IoT platforms would enable the investment to create great Arm-based server CPUs in the same way Intel was able to leverage x86 in the client business to take over server CPU business in the 90s and 00s.
Server functionality would ultimately come together into a single SoC. Thus to innovate in the cloud, AWS would need to innovate on silicon.
The ultimate conclusion was that AWS needed to do a custom Arm server processor. As an aside, it would be amazing if this document was released publicly on its 10-year anniversary to show how visionary it was.
Let’s expand on this thesis James Hamilton had and look at two key ways in which using AWS-designed, Arm-based CPUs could offer advantages compared to their external counterparts.
Firstly, they provide a way for AWS to reduce its costs and to offer better value to customers. How would it achieve this? Elaborating on James Hamilton’s points, it could tap into Arm’s scale in mobile by using the Arm-designed Neoverse cores. It can also utilize TSMC’s manufacturing scale, which far exceeds that of Intel, primarily due to the smartphone market. Using TSMC would, of course, also bring access to leading-edge process nodes, ahead of what Intel can make.
Our estimates have Amazon’s in-house Graviton 2 and 3 CPUs as nearly 1 million units in 2022. This alone is a respectable enough volume to justify an in-house CPU program with core design outsourced to Arm, especially as Amazon continues to substitute AMD and Intel CPU purchases with their own. Amazon’s vertical integration play is a no-brainer, even if the only benefit was cheaper CPUs.
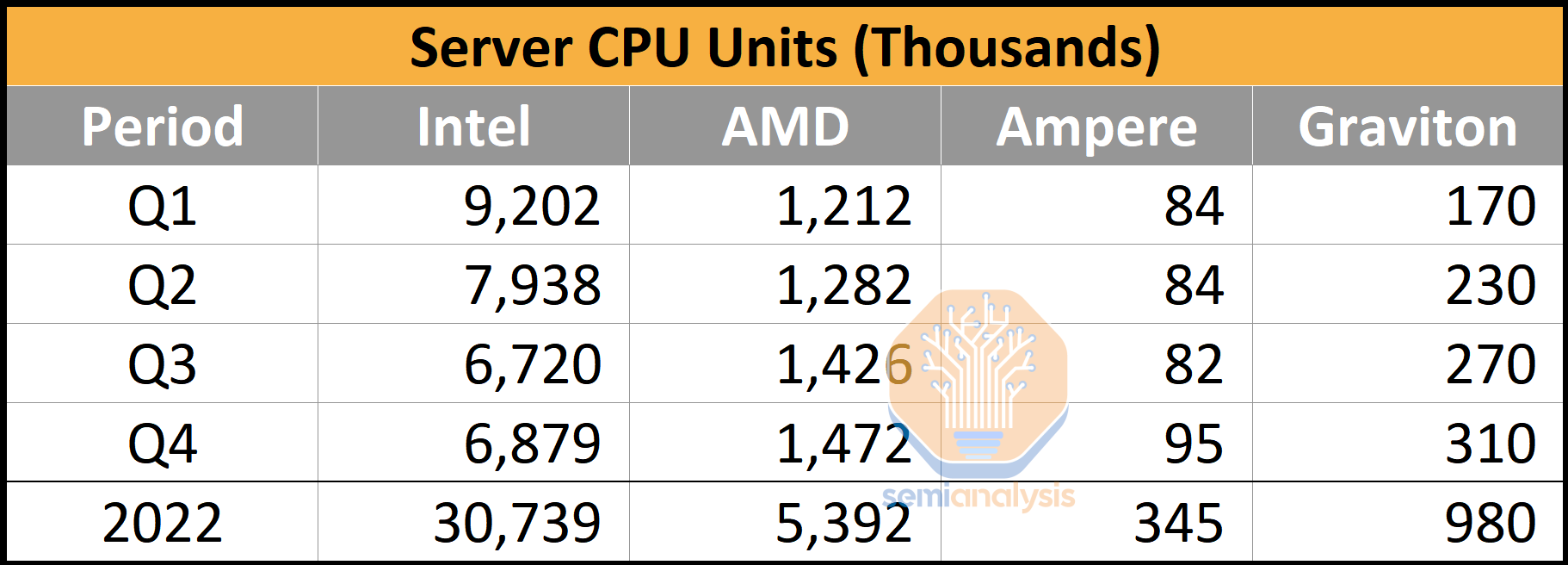
Comparing Amazon’s Graviton unit volume to the general market, and they are still currently dwarfed by Intel and AMD. While we believe Amazon has out-shipped Ampere Computing in the Arm server space with their in-house installations, there is still a big gap compared to the x86 vendors.
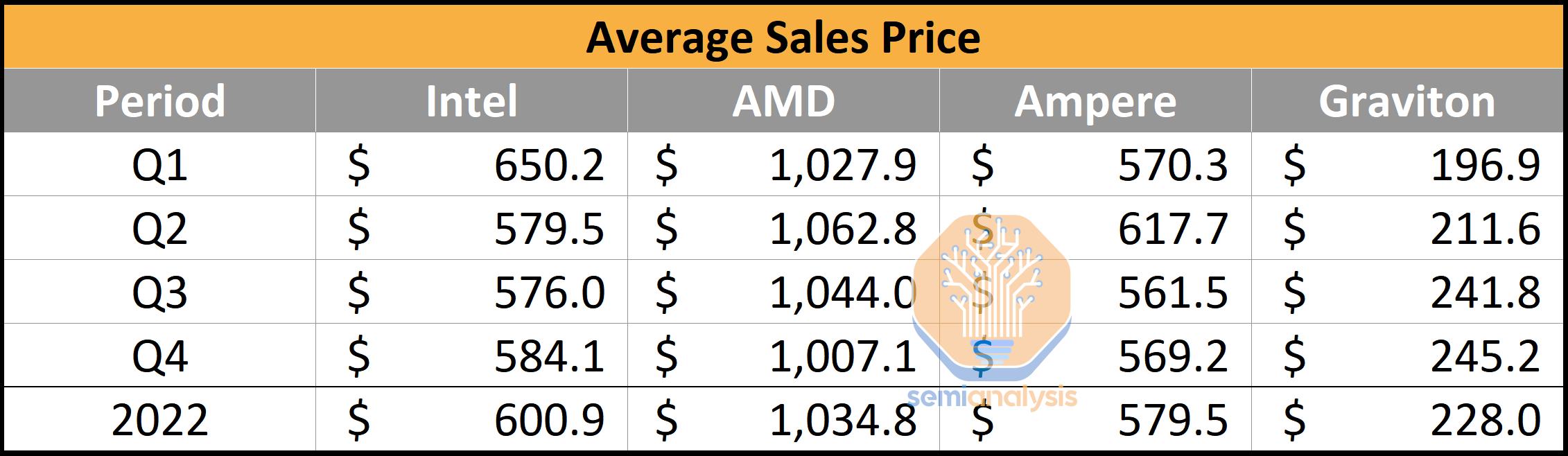
Now if we examine average sales prices, AMD commanded the highest sales price in the industry due to their high mix of 48-core and 64-core server CPUs with unmatched IO capabilities. Intel and Ampere Computing have similar ASPs, ranging around $600. We used our own estimates on manufacturing, packaging, and test costs for Graviton 2 and Graviton 3. Note IP licensing costs are not accounted for, but likely they aren’t that high, given Amazon has a sweetheart deal with Arm.
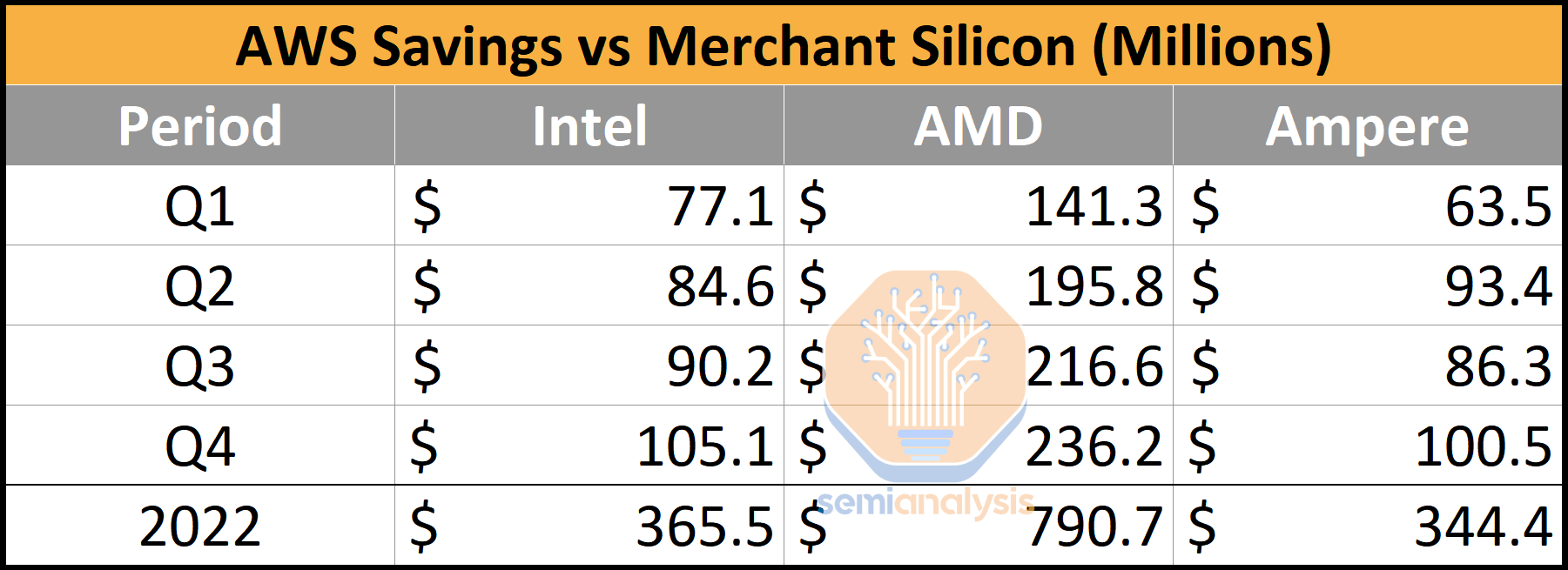
If CPUs were assumed to be 1-to-1 replacements, then the switch to in-house silicon by Amazon saves them hundreds of millions of dollars. Of course, not all CPUs are equal. Even AMD’s last generation Milan is still faster than Intel’s, Amazon’s, or Ampere’s current generation in many ways. Even ignoring the outlier that is AMD, the potential savings from Graviton in 2022 are >$300M. Now layer on the fact that Amazon’s CPUs are higher performance than Intel’s while also using less power, and the savings start to grow rapidly. We believe the total cost of development of Graviton is likely in the ~$100M annual range, which gives them >$200M of savings.
The merchant silicon providers are irreversibly losing hundreds of millions of dollars and soon billions of dollars in TAM. Intel is the biggest loser here, moving from a chip company selling millions of CPUs into the cloud to a manufacturing company that is doing the significantly lower margin packaging of these Graviton3 CPUs.
Just as important, in-house CPUs enables Amazon to design CPUs to maximize density and minimize server and system level energy, which helps tremendously on a total cost of ownership basis. One easy-to-understand engineering decision is that Amazon architected Graviton 3 to be only 64 cores, despite ample room to scale chip size and power up.
Contrast this with AMD’s 96-core Epyc, which is much faster, but also has higher power. Amazon’s conscious engineering decision enables them to put 3 CPUs per 1U server. Meanwhile, AMD Genoa servers max out at 2 CPUs per 1U, and due to power constraints, it often ends up being a 2U-sized server. Some of the more nuanced engineering choices which differ from AMD and Intel revolve around Graviton being cloud-native, which we explored more in detail here.
We shouldn’t forget, of course, that competition also increases the pressure on Intel and AMD to reduce prices on CPUs. AWS also saves on their x86 CPUs too! AMD and Intel must outengineer Amazon to such a large degree that they can justify their huge margins on merchant silicon. We have no doubts AMD is better at engineering CPU cores and SoCs, and Intel could get there too, but can they be >2x better to justify their ~60% datacenter margins? Tough proposition.
Microsoft and Google both have ongoing internal server CPU efforts on the horizon, but they have yet to install anything in volume. Even once they do, it’s hard to imagine they will be able to beat Amazon’s 3rd or 4th iteration.
The tremendous scale of Amazon, especially with regard to general-purpose compute and storage-related verticals, cannot be understated. This will continue to drive a durable advantage in the cloud for many years to come.
Check out The Chip Letter for a ton of great history lessons on semiconductors, Babbage helped us write a portion of the history here, and he will be releasing his own piece that goes over more of the history of Amazon’s in-house semiconductors soon.
The Next Era of Computing
So far, we have only sung praises about Amazon, but the background and realities of Amazon’s advantages had to be presented before we can even begin to talk about the future of cloud service providers.
Amazon, semiconductors, and tech, in general, are stories of stacking S curves. Amazon, as a company, is geared to constantly grow. They’ve never really exited the investment cycle. In many ways, they are culturally equipped to always find the next big thing, not necessarily extracting maximum value once their fangs are sunk in.
Amazon’s culture, conscious business decisions around their cloud service provider model, and technology choices with regard to custom compute and networking silicon could leave them hanging dry in the next era of computing. While the prior two eras of cloud will continue to play out and Amazon will extract huge value out of being the leading unregulated utility in an oligopoly-like market, the next era is not necessarily theirs for the taking. There is significant competitive pressure from existing competitors and new ones who are racing ahead.
The second half of this report is for subscribers and will go in-depth about major technical deficiencies in Amazon’s silicon strategy and how they are missing the next era of explosive growth in both AI and services. We will be comparing the silicon, server, and cloud strategies of multiple competitors, including Microsoft Azure, Nvidia Cloud, Google Cloud, Oracle Cloud, IBM Cloud, Equinix Fabric, Coreweave, and Lambda. Furthermore, we will have a discussion about the services business and how competitors are more equipped to lead there. We will share multiple viewpoints and, ultimately, how we see the market shaking out. Furthermore, we will share some short-term commentary on cloud, AI, and services as well.