


Advanced Packaging Part 2 - Review Of Options/Use From Intel, TSMC, Samsung, AMD, ASE, Sony, Micron, SKHynix, YMTC, Tesla, and Nvidia
Advanced Packaging Part 2 - Review Of Options/Use From Intel, TSMC, Samsung, AMD, ASE, Sony, Micron, SKHynix, YMTC, Tesla, and Nvidia

Advanced packaging exists on a continuum of cost and throughput vs performance and density. In the first part of the series, we spoke through the need for advanced packaging. Even though the demand for advanced packaging is obvious, there is an incredible number of advanced packaging types and brand names from Intel (EMIB, Foveros, Foveros Omni, Foveros Direct), TSMC (InFO-OS, InFO-LSI, InFO-SOW, InFO-SoIS, CoWoS-S, CoWoS-R, CoWoS-L, SoIC), Samsung (FOSiP, X-Cube, I-Cube, HBM, DDR/LPDDR DRAM, CIS), ASE (FoCoS, FOEB), Sony (CIS), Micron (HBM), SKHynix (HBM), and YMTC (XStacking). These packaging types are used by all of our favorite companies from AMD, Nvidia, and many more. In Part 2, we will explain all these types of packaging and their uses. In part 3 of the deep dive, we analyzed the TCB market including Intel’s role, HBM, ASM Pacific, Besi, and Kulicke and Soffa.
As a reminder for those of you on the email list, read it in a browser, as the email will be clipped and miss updates.
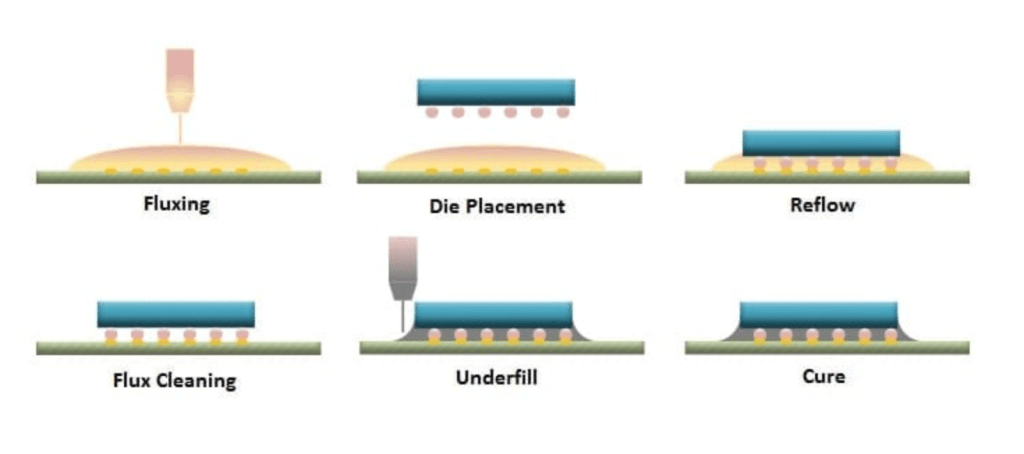
Flip chip is the one of the common form of packaging after wire bonding. It is offered by a wide array of firms from foundries, integrated design manufacturers, and outsourced assembly and test firms. In flip chip, a PCB, substrate, or another wafer will have landing pads. A chip is then placed accurately on top with the bumps contacting the landing pads. The chip is sent to a reflow oven which heats up the assembly and reflows the bumps to bond the two together. The flux is cleaned away and an underfill is deposited in between. This is just a basic process flow, as there are many different types of flip chip including but not limited fluxless.
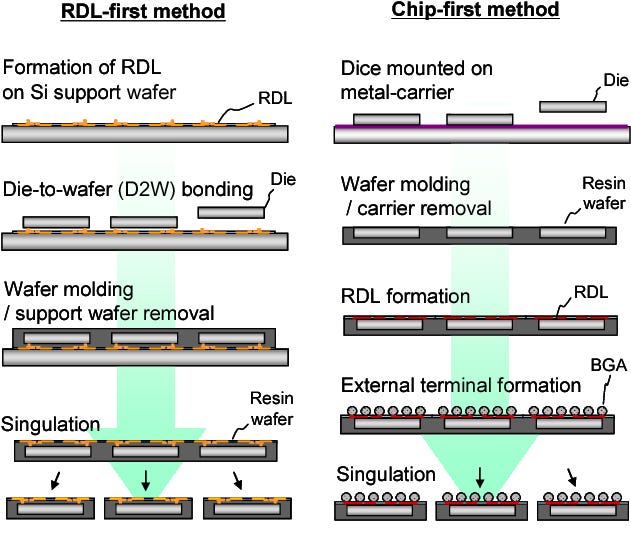
While flip chip is extremely common, advanced versions with less than 100-micron pitches are less so. In regard to the definition of advanced packaging we established in part 1, only TSMC, Samsung, Intel, Amkor, and ASE are involved with very high volumes of logic advanced packaging utilizing flip chip technologies. 3 of these firms are also manufacturing the complete silicon wafers while the other two are outsourced assembly and test (OSAT).
This is where a flood of different types of flip chip packaging types start to come in. We will use TSMC as the example then expand out and compare other firms packaging solutions to TSMC’s. The biggest difference across all of TSMC’s packaging options is related to the substrate material, size, RDL, and stacking.
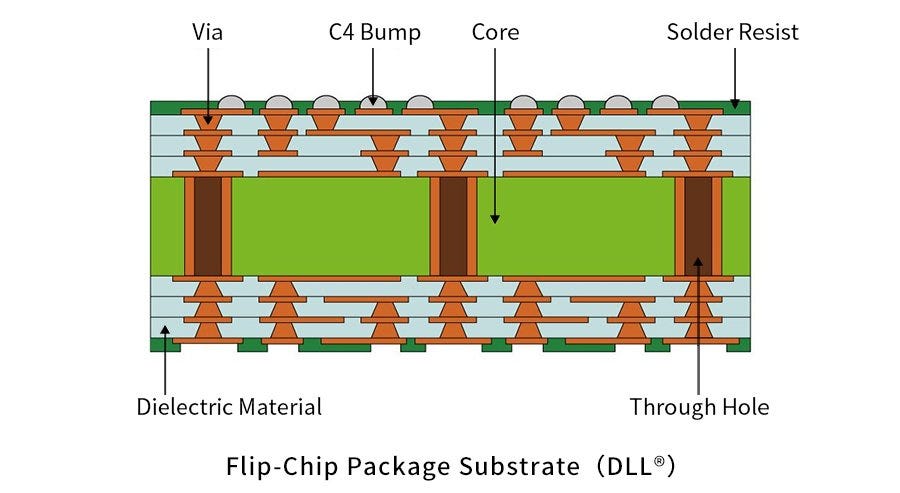
In standard flip chip, the most common substrate is generally an organic laminate which is then clad with copper. From here, the wiring is built up around the core on both sides, the most discussed being Ajinomoto build-up films (ABF). This core has many layers built up on top and these layers are responsible for redistributing signals and power across the package. These layers carrying the signals are built using dry film lamination and patterning using CO2 lasers or UV lasers.

This is where TSMC’s expertise starts to come in with their integrated fan outs (InFO). Rather than using the standard flow with ABF films, TSMC uses a process that is more tied to silicon manufacturing. TSMC will lithographically define the redistribution layers using Tokyo Electron coater/developers, Veeco lithography tools, Applied Materials Cu deposition tools. The redistribution layers are smaller and denser than what most OSATs can produce and therefore can accommodate more complex wiring. This process is called fan out wafer level packaging (FOWLP). ASE, the largest OSAT, offer FoCoS (fan out chip on substrate), a form of FOWLP, which also utilizes the silicon manufacturing techniques. Samsung also has their fan out system in package (FOSiP) which is mainly used in smartphones, smartwatches, communications, and automotive. Most smartphones include fanouts from ASE, Amkor, Samsung, or TSMC.
With InFO-R (RDL), TSMC can package a chip with high IO density, complex routing, and/or multiple chips. The most common products with InFO-R are Apple iPhone and Mac chips, but there are a wide variety of mobile chips, communications platforms, accelerators, and even networking switch ASICs. Samsung has also gotten wins in the networking switch ASIC fanout market with Cisco Silicon One. The advancements moving forward with InFO-R will mostly relate to scaling to larger package sizes with more power consumption and IO.

Edited April: There have been quite a few rumors that AMD will move to fan out packaging for their upcoming Zen 4 client (pictured above) and server CPUs. SemiAnalysis attempted to confirm that Zen 4 based desktop and server products will use a fan out. This package will then be packaged traditionally on top of a standard organic substrate which will have LGA pins on the bottom of this. The company packaging these products and technical reason for moving or not moving to fan out will be revealed behind the paywall.
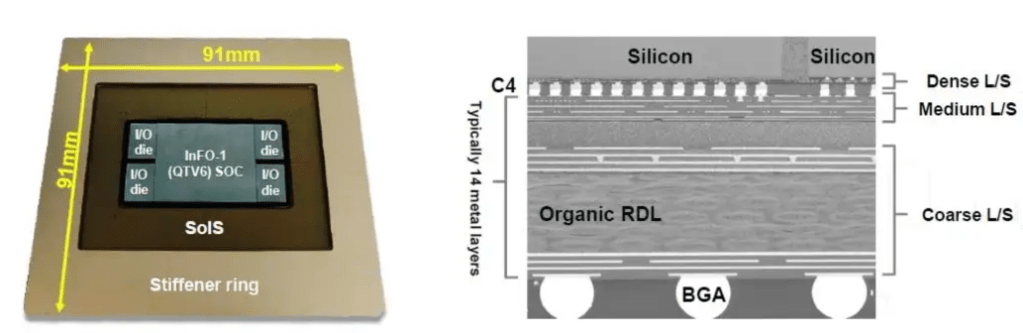
A standard package will have the core substrate followed by 2 to 5 levels of redistribution layers (RDL) on each side, including more advanced integrated fanouts. TSMC’s InFO-SoIS (system on integrated substrate) takes this concept to the next level. It offers up to 14 redistribution layers (RDL) which enables very complex routing between dies. There is an additional layer of higher density routing layers on the substrate near the dies.

TSMC also offers InFO-SOW (system on wafer) which allows for the fanout the size of an entire wafer that packs dozens of chips. We wrote about the Tesla Dojo 1 which utilizes this specialized form of packaging. We also exclusively disclosed the use of this technology weeks before Tesla unveiled it at their AI Day last year. Tesla will be utilizing a Samsung FOSiP for HW 4.0.

Lastly in TSMC’s lineup of integrated fanouts, there is InFO-LSI (local silicon interconnect). InFO-LSI is InFO-R, but with a piece of silicon beneath multiple dies. This local silicon interconnect will start off as a passive interconnect between multiple dies, but it can evolve into being active (transistors and various IP) in the future. It will also eventually scale down to 25-micron, but we do not believe that will be the case in the first generation. The first public product with this type of packaging will be revealed behind the paywall.
The immediate comparison that pops into mind is most likely with Intel’s EMIB (Embedded multi-die interconnect bridge), but that isn’t really the best choice. It is more like Intel’s Foveros Omni or ASE’s FOEB. Let us explain.

Intel’s embedded multi-die interconnect bridge is placed into a traditional organic substrate cavity. The substrate then continues to be built up. While this can be done by Intel, the EMIB placement and build up can also be done by traditional organic substrate suppliers. Due to the large landing pads on the EMIB die and the method for depositing the laminate wiring and vias, incredibly accurate placement of die on the substrate isn’t needed.

Intel forgoes more expensive silicon substrate materials and silicon manufacturing processes by continuing to use existing organic laminate and ABF supply chains. In general, this supply chain is commoditized, although it’s quite tight currently given shortages. Intel’s EMIB has been shipping since 2018 in products including Kaby Lake G, a variety of FPGAs, Xe HP GPUs, and certain cloud server CPUs including Sapphire Rapids. Currently all EMIB products use 55-micron, but the 2nd generation is 45-micron and 3rd generation is 40-micron.

Intel can push power through this die to the active dies above. Intel also has the flexibility to design the package to function without EMIB and certain chiplets if needed. Some teardowns of Intel’s FPGAs have found that Intel will not place the EMIB and active die if the SKU Intel is shipping does not demand it. This allows some optimization around the bill of materials for certain segments. Lastly, Intel also can save on manufacturing costs by only utilizing silicon bridges where needed. This contrasts with TSMC’s CoWoS which has all die placed on top of a single massive passive silicon bridge. More on this later, but the single largest differentiator between TSMC’s InFO-LSI and Intel’s EMIB is choice of substrate materials and manufacturing process.

To make things even more complicated, ASE has their own 2.5D packaging technology as well that is distinctly different from Intel’s EMIB and TSMC’s InFO-LSI. It is being used in AMD’s MI200 GPU which will be going into multiple high-performance computers including the US Department of Energy’s Frontier exascale system. ASE’s FOEB packaging technology is more similar to TSMC’s InFO-LSI in that it is also a fan out. TSMC use standard silicon manufacturing techniques to construct the RDL. One major difference is ASE uses a glass carrier panel rather than silicon. This is a cheaper material, but it also has some other benefits which we will discuss later.
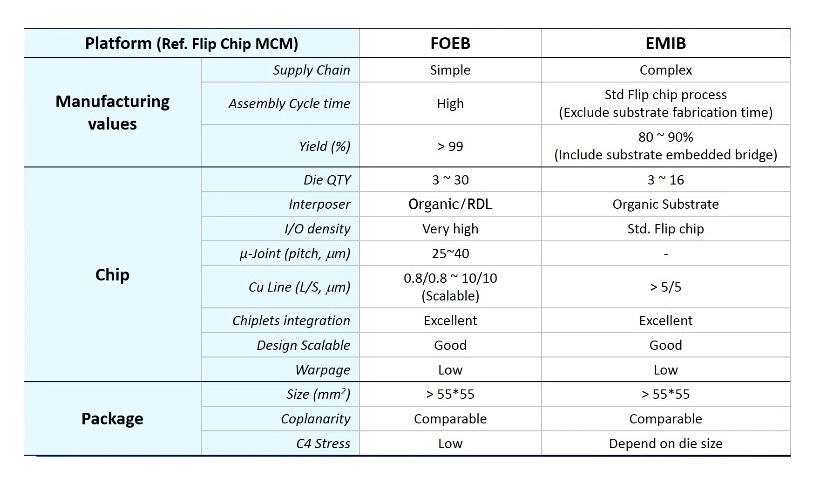
Rather than embedding the passive interconnect die within a cavity in the substrate, ASE places the die, builds up copper pillars + solder cap, then builds up the entire RDL. On top of the RDL, the active silicon GPU dies and HBM dies are placed using micro-bumps for connections. The glass interposer is then removed from the package with a laser release process and then the other side of the package is complete before it is mounted onto an organic substrate using the standard flip chip process.
ASE makes many claims about FOEB versus EMIB, but some are downright wrong. It’s some understandable that ASE need to market their solutions, but let’s cut through the noise. EMIB yields are not in the 80% to 90% range. EMIB’s yields are near 100%. First generation EMIB does have a scaling limit in terms of number of die, but 2nd generation does not. In fact, Intel will be releasing a product with the largest package ever, an advanced package that is 92mm by 92mm BGA package using the 2nd generation EMIB. FOEB does retain advantages in routing density and die to package bump size by using a fanout and lithographically defined RDL through the whole package, but that is also more costly.
Versus TSMC, the biggest difference seems to be the initial glass substrate material versus silicon. Part of this is likely due to ASE having more cost constrained. ASE has to win customers over by offering great technology for less. TSMC is a master of silicon and focuses on the technology they know well, silicon. TSMC has the culture of pushing technology to the furthest bounds, and it was better for them to choose silicon on this push forward.

Now back to TSMC’s other advanced packaging options because we still have a few more to go. The CoWoS platform also has CoWoS-R and CoWoS-L platforms. These correspond nearly 1 to 1 with InFO-R and InFO-L. The distinction between these two has more to do with process. InFO is a chip first process where the chip is placed first, then build the RDLs are built around it. With CoWoS, the RDLs are built up then the chip is placed. The distinction is not that important for most folks trying to understand advanced packaging, so we will breeze by that topic today.
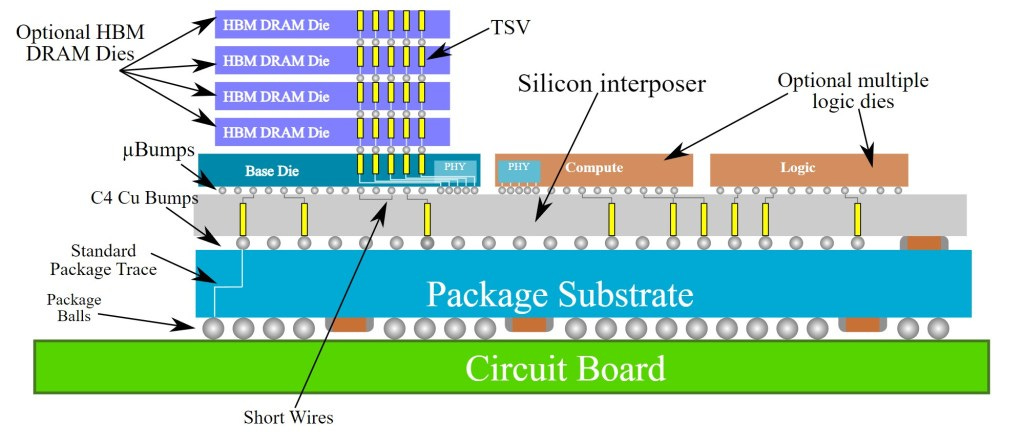
The big showstopper is CoWoS-S (Silicon Interposer). It involves taking a known good die, flip chip packaging it onto a passive wafer which has wires patterned in it. This is where the name CoWoS comes from, Chip on Wafer on Substrate. It is the highest volume 2.5D packaging platform out there by a long shot. As discussed in part 1, this is because Nvidia datacenter GPUs such as P100, V100, and A100 utilize CoWoS-S. While Nvidia has been the highest volume, Broadcom, Google TPU, Amazon Trainium, NEC Aurora, Fujitsu A64FX, AMD Vega, Xillinx FPGAs, Intel Spring Crest, and Habana Labs Gaudi are just a few more notable examples of CoWoS usage. Most compute heavy chips with HBM, including AI training chips from a variety of startups use CoWoS.
Just to further hammer home the point on how pervasive CoWoS really is, here’s a few quotes from Alchip. Alchip is a Taiwanese design and IP firm who primarily assists in EDA, physical design, and capacity work related to Alchips utilizing TSMC’s CoWoS platform. These quotes come from Alchip, but Doug O'laughlin of Fabricated Knowledge alerted us of them in his excellent analysis.
And we are not allowed to give it (financial guidance) because of the TSMC requesting us not to deliver any numerical guidance to the market.
Alchip, a public firm, is not allowed to give guidance because TSMC said so…
mass production forecast, we received an incredible high volume from key customers. Number is too large to digest. Honestly, if we can hit, yes we can easily hit another home run if we can get the support from supplier to fulfill just 50% of their forecast. Yes honestly, the NP forecast we receive is incredibly high.
Alchip is incredibly limited in capacity, namely CoWoS
In fact, if a (single cloud) customer come to them individually, they (TSMC) deny all the meeting, but they still work on Alchip. The reason they want to work with us because we are representing more than 30 customers. So yes they need -- they also need to diversify their business concentration. So I think we get -- we can say we get a great support, but of course not 100%. Because all the capacity is booked by the tier 1 customer Daniel mentioned before.
TSMC doesn’t even take every meeting related to CoWoS capacity because TSMC already sells everything they make, and it would be too much engineering time to support all those designs. On the other hand, TSMC has high customer concentration (Nvidia), so TSMC wants to work with other firms. Alchip sort of works as the middleman, and even though the tier 1 customer (Nvidia) booked everything, Alchip still get some capacity. Even then, they are only getting 50% of what they want.
Let’s turn around and look at what Nvidia is doing. In Q3, their long-term supply obligations jumped up to $6.9B, and more importantly, Nvidia made $1.64B of prepayments and will be making another $1.79B of prepayments in the future. Nvidia is gobbling up supply, specifically for CoWoS.
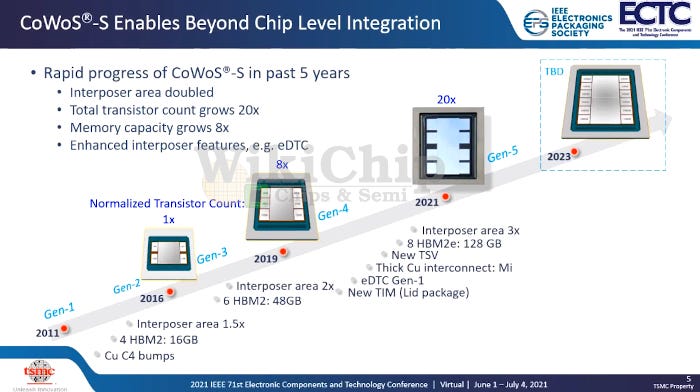
Back to the technology, CoWoS-S has gone through an evolution over the years. The main marque is the interposer area becoming larger. Because the CoWoS platform uses Silicon manufacturing techniques, it abides by a principal called reticle limit. The maximum size a chip can be printed with 193nm ArF lithography tool is 33mm by 26mm (858mm2). A silicon interposer is also lithographically defined for its main purpose, very dense wires connecting chips that sit atop it. Nvidia’s chips have long since approached the reticle limit themselves, yet still need to connect to on package high bandwidth memory.

The image above contains a Nvidia V100, Nvidia's 4 year old GPU which is 815mm2. Once the HBM is included, it extends beyond the reticle limit that a lithography tool can print, yet TSMC figured out how to connect them. TSMC achieves this by doing something called reticle stitching. TSMC has grown their capabilities here and can ship 3x the size of a reticle for silicon interposers. Given limitations of reticle stitching, the Intel EMIB, TSMC LSI, and ASE FOEB approaches have merits. They also do not have to deal with as much expense of a large silicon interposer.

In addition to increasing the reticle size, they have made other enhancements such as changing the micro-bumps to copper from solder for improved performance/power efficiency, iCap, a new TIM/lid package, and more.
There’s an interesting story about the TIM/lid packaging. With the Nvidia V100, Nvidia had a pervasive HGX platform which would ship to many server ODMs and then out to datacenters. The torque one could apply to coolers screws to achieve the correct mounting pressure was very specific. These server ODMs were overtightening the coolers and cracking dies on these $10k GPUs. Nvidia with their A100 moved to a package that had a lid over the die rather than direct die cooling. The issue with this type of packaging crop up with Nvidia’s A100 and future Hopper DC GPUs when they still needed to dissipate a huge amount of heat. There is a lot of optimizations that had to go on between TSMC and Nvidia on the packaging to deal with this. Anyways, we will have some information on the packaging and power requirements on the next generation Hopper GPUs behind the paywall.
Samsung also has their I-Cube technology which is similar to CoWoS-S. The only major customer Samsung has for this packaging is Baidu for their AI accelerators.

Next we have Foveros. This is Intel’s 3D chip stacking technology. Instead of one die being active on top of another die which is essentially just dense wires, Foveros involves both dies containing active elements. With this, Intel’s first generation Foveros launched in the Lakefield hybrid CPU SOC in June of 2020. This chip wasn’t especially high volume or breath taking, but it was a chip of many first for Intel including 3D packaging and their first hybrid CPU core architecture with a big performance core and small efficiency cores. It utilized a 50-micron bump pitch.

The next Foveros product is Ponte Vecchio GPU which after many delays, should be due out this year. It will include 47 different active chiplets packaged together with EMIB and Foveros. The Foveros die to die connections are at a 36-micron bump pitch.
In the future, most of Intel’s client lineup will use 3D stacking technologies including client products codenamed Meteor Lake, Arrow Lake, Lunar Lake. Meteor Lake will be the first product with Foveros Omni and a 36-micron bump pitch. The first datacenter CPU including 3D stacking technology is codenamed Diamond Rapids which follows Granite Rapids. We discuss what nodes some of these products utilize as well as Intel’s relationship with TSMC in this article.

Foveros Omni’s full name is Foveros Omni-Directional Interconnect (ODI). It bridges the gap between EMIB and Foveros while also offering some new features. Foveros Omni can function as an active bridge die between two other chips, as an active die that is fully underneath another die, or on top of another die but overhanging. David Schor does a good job breaking down the various kinds here.
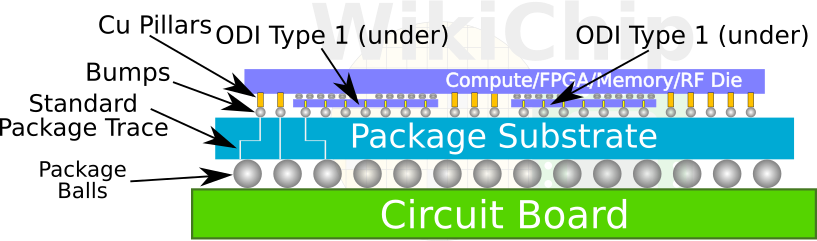
Foveros Omni is never embedded inside the substrate like EMIB, it sits full on top of it in every instance. The types of stacking leads to a problem where the package substrate has varying height connections to the chip sitting upon it. Intel developed a copper pillar technique that lets them transport signal and power to different z heights and through dies so chip designers can have more freedom when designing 3D heterogenous chips. Foveros Omni will start at a 36-micron bump pitch, but it will move down to 25-micron in a future generation.
We want to note that DRAM also uses advanced 3D packaging. HBM has been using advanced packaging for years across Samsung, SK Hynix, and Micron. The memory cells will be made and connect to TSVs which are revealed and have micro-bumps formed. More recently, Samsung has even began introducing stacks of DDR5 and LPDDR5X which utilize similar stacking technologies to pump up capacity higher. SKHynix HBM 3 will start with 12 dram dies vertically stacked with each dram die at 30-micron thickness. SKHynix will also be introducing hybrid bonding eventually in HBM 3. SKHynix will bond 16 chips together and each die will need to be even thinner.

Hybrid bonding is a technology where instead of using bumps, the chip is directly connected with through silicon vias. If we refer back to the flip chip process, there is no bump formation, flux, reflow, or under mold to fill the area between chips. Copper directly meets copper, end of story. The actual process is very difficult and partially detailed above. We will dive more into the tool ecosystem and types of hybrid bonding in the next part of this series. Hybrid bonding enables denser integration than any other packaging method described before this.
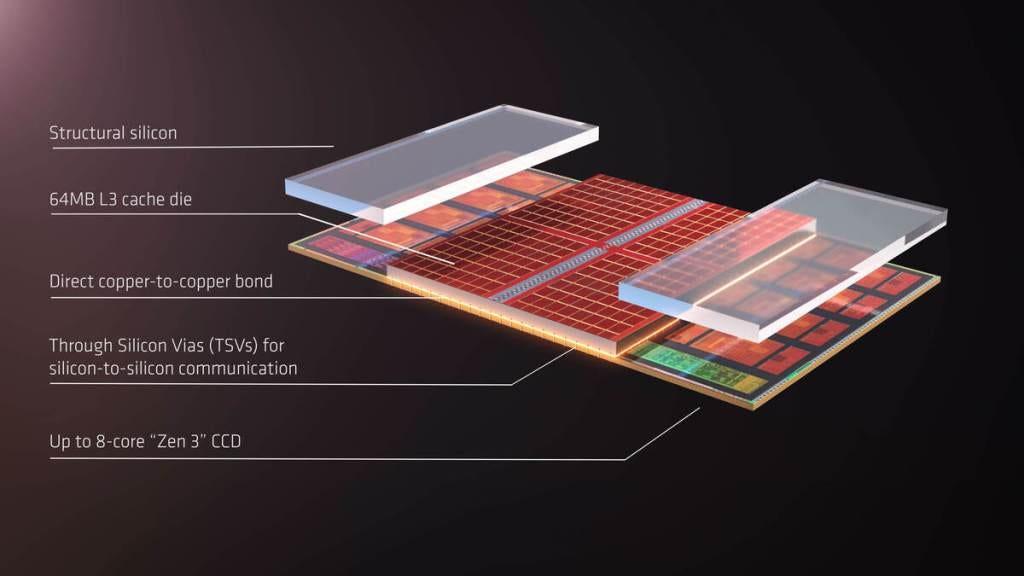
The most famous hybrid bonded chip is of course the recently announced AMD’s 3D stacked cache which is set to release later this year. This utilizes TSMC’s SoIC technology. Intel’s branding for hybrid bonding is called Foveros Direct and Samsung’s version is called X-Cube. Global Foundries publicized test chips with Arm using hybrid bonding. The highest volume hybrid bonded semiconductor company is not TSMC, and it won’t be TSMC this year or even next year. The company that ships the most units of hybrid bonded chips is actually Sony with their CMOS image sensors. In fact, you likely have a device in your pocket that contains a hybrid bonded CMOS image sensor assuming you have a high-end phone. As detailed in part 1, Sony has scaled the pitch down to 6.3-micron while AMD’s V-cache is at 17-micron pitch.
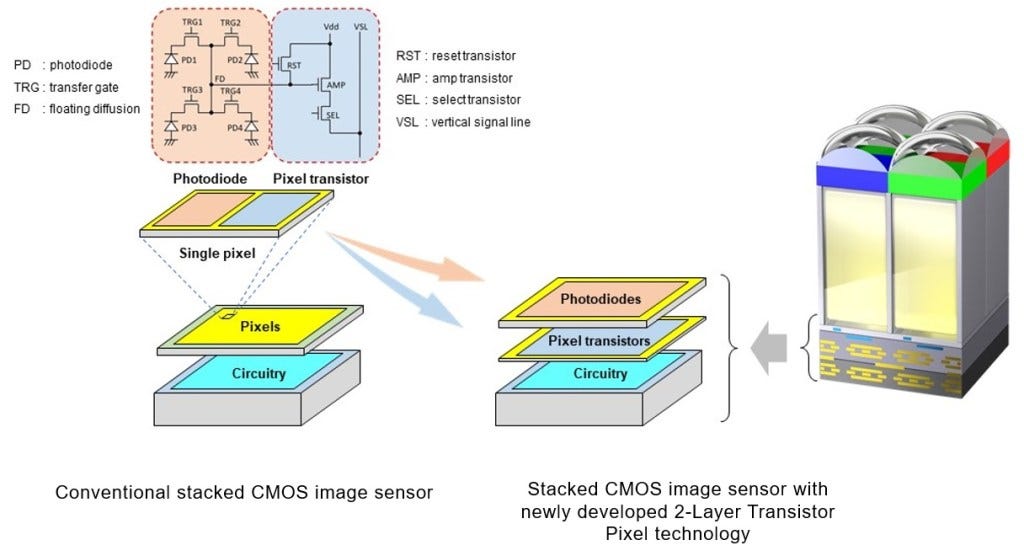
Currently Sony ships 2 stack and 3 stack versions. In the 2 stack, the pixels are on top of the circuitry. In the 3 stack version, pixels are stacked on top of a DRAM buffer cache which is on top of the circuitry. Advancements continue, as Sony looks to split apart the pixel transistors from the circuitry and create even more advanced cameras with up to 4 layers of silicon. The image above showcases Sony’s sequential stacking which is done with a 0.7-micron pitch!
Another upcoming high-volume application of hybrid bonding is from Yangtze Memory Technology Corporation’s Xtacking. YMTC stacks the CMOS periphery underneath the NAND gates using a wafer to wafer bonding technology. We detailed the benefits of this technology here, but in short, it allows YMTC to fit more NAND cells given a certain number of layers of NAND than any other NAND manufacturer including Samsung, SK Hynix, Micron, Kioxia, and Western Digital.
There is a lot to be said about various types of flip chip, thermocompression bond, and hybrid bonding tools, but we will save that for our next parts. The common investor knowledge about Besi Semiconductor, ASM Pacific, Kulicke and Soffa, EV Group, Suss Microtec, SET, Shinkawa, Shibaura, Xperi, and Applied Materials is not correct and the diversity of tool usage by the various firms and packaging types here is very broad. The winners are not as obvious as it seems.
Behind the paywall is details about the first customer/products to use InFO-LSI, Zen 4 packaging, Nvidia Hopper details including node, power, packaging, and more.